

Um algoritmo de ordenação é uma sequência finita e bem definida de instruções que reorganiza os elementos de uma coleção (lista, array, vetor) segundo um critério de comparação, geralmente ordem crescente ou decrescente. É um dos pilares da ciência da computação porque praticamente todo software moderno depende de dados ordenados em algum ponto: bancos de dados que indexam registros, sistemas de busca que retornam resultados por relevância, e-commerces que listam produtos por preço, planilhas que classificam linhas por coluna. Sem ordenação eficiente, operações como busca binária, junções de tabelas e renderização de listas tornam-se inviáveis em escala.
A escolha do algoritmo certo impacta diretamente a performance da aplicação. Ordenar 10 milhões de linhas com Bubble Sort pode levar horas, enquanto Quick Sort ou Merge Sort resolvem o mesmo problema em segundos. Conhecer os tipos, a complexidade computacional (notação Big O) e os trade-offs entre tempo, memória e estabilidade é fundamental para qualquer desenvolvedor que trabalhe com volume real de dados.
Como funciona um Algoritmo de Ordenação?
Todo algoritmo de ordenação opera sobre uma estrutura de dados linear e aplica uma função de comparação entre pares de elementos. O resultado dessa comparação determina se há troca de posições, inserção em outra estrutura ou particionamento da coleção. As variações entre algoritmos surgem da estratégia adotada para reduzir o número total de operações necessárias.

Comparação vs Distribuição
Algoritmos baseados em comparação (Bubble Sort, Quick Sort, Merge Sort, Heap Sort) usam operadores relacionais (<, >, =) para decidir a ordem. O limite teórico inferior desses algoritmos é O(n log n), provado matematicamente por árvores de decisão. Já os algoritmos de distribuição (Radix Sort, Counting Sort, Bucket Sort) não comparam elementos diretamente — eles distribuem valores em baldes ou processam dígitos individualmente, conseguindo complexidade linear O(n+k) sob certas restrições de domínio dos dados.
In-place vs Out-of-place
Um algoritmo in-place ordena a coleção sem alocar memória adicional significativa — usa apenas O(1) ou O(log n) de espaço auxiliar. Quick Sort e Heap Sort são exemplos clássicos. Já algoritmos out-of-place precisam de uma estrutura auxiliar do tamanho da entrada, como o Merge Sort tradicional, que requer O(n) de memória extra. Em cenários com restrição de RAM (sistemas embarcados, processamento de arquivos gigantes), a escolha entre in-place e out-of-place é decisiva.
Estabilidade
Um algoritmo é estável quando preserva a ordem relativa de elementos com chaves iguais. Imagine uma lista de pedidos já ordenada por data e que precisa ser reordenada por valor — se o algoritmo for estável, pedidos com o mesmo valor manterão a ordem cronológica original. Merge Sort, Insertion Sort e Bubble Sort são estáveis. Quick Sort e Heap Sort, em suas implementações canônicas, não são. Essa propriedade é crítica em ordenações multinível e em sistemas que dependem de ordenações sucessivas.
Para que servem os Algoritmos de Ordenação?
A aplicação prática de algoritmos de ordenação atravessa praticamente todas as camadas de software corporativo. Em bancos de dados relacionais como MySQL e PostgreSQL, cláusulas ORDER BY disparam algoritmos internos otimizados (geralmente variações de Quick Sort ou Merge Sort externo) para retornar resultados ordenados ao cliente. Quando a query envolve volumes que excedem a memória disponível, o engine recorre a Merge Sort externo, dividindo o conjunto em chunks ordenados em disco e mesclando-os sequencialmente.
Na indexação, índices B-Tree (estrutura padrão do MySQL/InnoDB) mantêm chaves ordenadas para permitir busca binária em O(log n). A construção inicial desses índices durante operações como CREATE INDEX ou ALTER TABLE envolve ordenação massiva. Em e-commerces B2B com milhões de SKUs, a velocidade dessa ordenação inicial determina quanto tempo de downtime a manutenção exige.

E-book – Tudo sobre Automação de Marketing
E-book – Tudo sobre Automação de Marketing
Mais Informações
Na exibição de dados em interfaces, listas ordenadas por relevância, preço, data ou popularidade são geradas a cada requisição. Frameworks JavaScript modernos (Vue, React) frequentemente delegam ordenação ao client-side com Array.prototype.sort(), que em motores V8 usa TimSort — um híbrido de Merge Sort e Insertion Sort otimizado para dados parcialmente ordenados, comum em datasets reais.
Principais algoritmos de ordenação
Bubble Sort
O Bubble Sort percorre a lista repetidamente comparando pares adjacentes e trocando-os se estiverem fora de ordem. A cada passagem completa, o maior elemento ainda não posicionado borbulha até o final. Tem implementação trivial (cerca de 5 linhas), mas complexidade O(n²) no caso médio e pior caso, tornando-o inviável para n acima de alguns milhares. Sua relevância hoje é didática e em casos muito específicos com listas quase ordenadas, onde uma versão otimizada pode atingir O(n) no melhor caso.
Quick Sort
O Quick Sort aplica a estratégia de divisão e conquista: escolhe um elemento pivô, particiona o array em duas partes (menores que o pivô e maiores que o pivô) e aplica recursivamente o mesmo processo em cada partição. Com pivô bem escolhido (mediana de três, randomização), atinge O(n log n) no caso médio com baixa constante multiplicativa, sendo na prática um dos algoritmos mais rápidos. O ponto fraco é o pior caso O(n²), que ocorre quando o pivô é sempre o menor ou maior elemento — situação evitada por implementações modernas com pivô aleatório ou IntroSort, que troca para Heap Sort se a recursão fica profunda demais.
Merge Sort
O Merge Sort também usa divisão e conquista, mas de forma diferente: divide a lista ao meio recursivamente até obter sublistas de tamanho 1, depois mescla as sublistas duas a duas mantendo a ordem. Garante O(n log n) em todos os casos (melhor, médio e pior), é estável e paraleliza bem — características que o tornam padrão em ordenação externa de grandes datasets e em linguagens funcionais. O custo é a memória adicional O(n), o que pode ser proibitivo em ambientes com restrição severa de RAM.
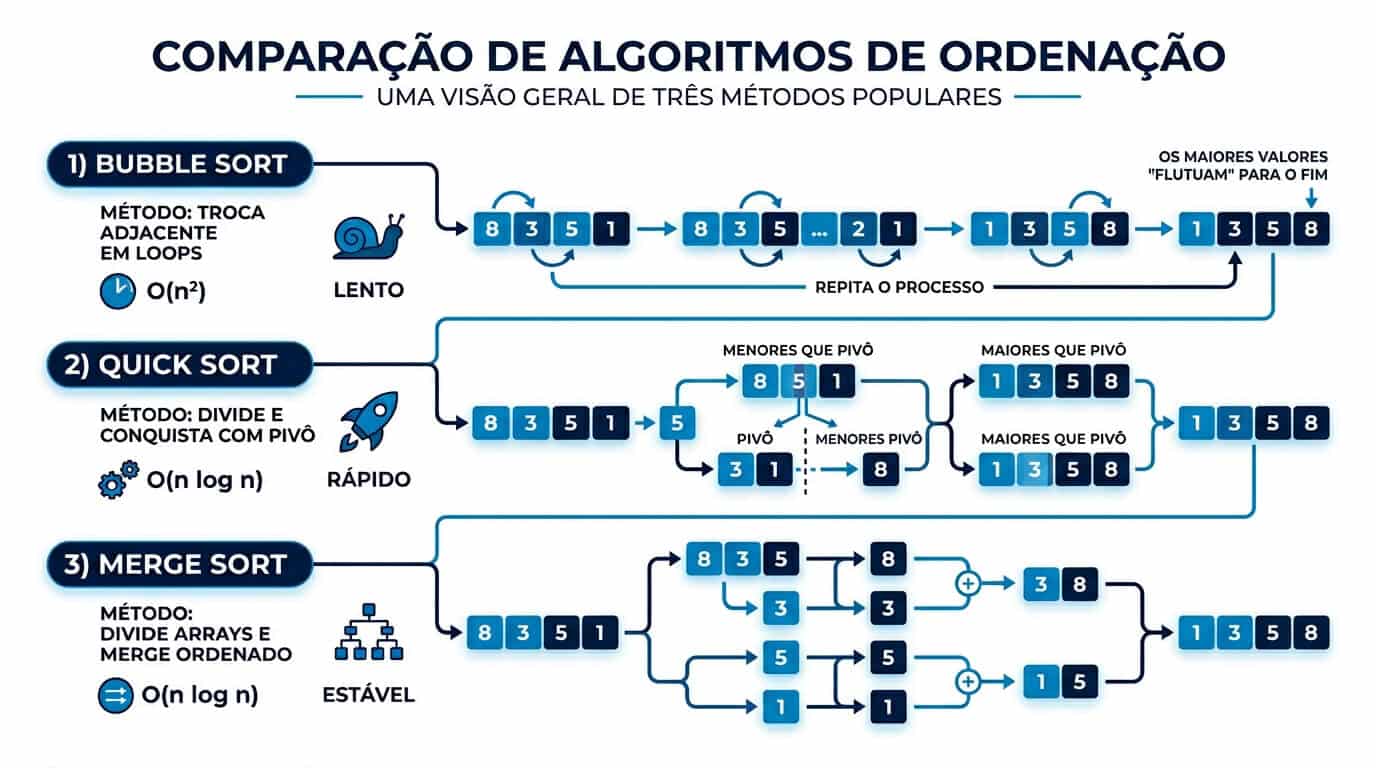

Tabela comparativa de complexidades (Big O)
| Algoritmo | Melhor caso | Caso médio | Pior caso | Memória | Estável |
|---|---|---|---|---|---|
| Bubble Sort | O(n) | O(n²) | O(n²) | O(1) | Sim |
| Insertion Sort | O(n) | O(n²) | O(n²) | O(1) | Sim |
| Selection Sort | O(n²) | O(n²) | O(n²) | O(1) | Não |
| Quick Sort | O(n log n) | O(n log n) | O(n²) | O(log n) | Não |
| Merge Sort | O(n log n) | O(n log n) | O(n log n) | O(n) | Sim |
| Heap Sort | O(n log n) | O(n log n) | O(n log n) | O(1) | Não |
| TimSort | O(n) | O(n log n) | O(n log n) | O(n) | Sim |
| Radix Sort | O(nk) | O(nk) | O(nk) | O(n+k) | Sim |
A leitura prática dessa tabela: para listas pequenas (n < 50), Insertion Sort é frequentemente mais rápido que Quick Sort por sua baixa constante. Para listas médias e grandes, Quick Sort domina em performance bruta, mas perde estabilidade. Quando estabilidade é obrigatória ou quando o pior caso precisa ser garantido, Merge Sort ou TimSort são as escolhas seguras.
Vantagens e desvantagens
Vantagens gerais dos algoritmos de ordenação:
- Habilitam busca binária, reduzindo busca de O(n) para O(log n)
- Aceleram operações de junção (JOIN) em bancos de dados
- Permitem detecção rápida de duplicatas em uma única passagem
- Facilitam visualização e análise de dados pelo usuário final
- São base para algoritmos mais sofisticados (mediana, percentis, k-ésimo menor)
Desvantagens e limitações:
- Custo computacional alto em datasets enormes sem indexação prévia
- Algoritmos in-place mais rápidos sacrificam estabilidade
- Algoritmos estáveis e garantidos (Merge Sort) consomem memória extra
- Implementações ingênuas (Bubble, Selection) escalam mal e podem travar aplicações
- Ordenação em disco (externa) introduz latência de I/O significativa
Erros comuns ao trabalhar com algoritmos de ordenação
1. Usar Bubble Sort em N grande: ainda é comum encontrar Bubble Sort em código de produção por inércia didática. Para n=100.000, ele executa cerca de 10 bilhões de operações — Quick Sort resolveria o mesmo em ~1,7 milhão. Diferença de 5.000x.
2. Ignorar estabilidade em ordenações multinível: ordenar primeiro por data e depois por categoria com algoritmo instável destrói o ordenamento por data dentro de cada categoria. O resultado parece correto à primeira vista, mas está errado. Sempre validar se o algoritmo escolhido preserva ordem relativa quando necessário.

3. Recursão profunda demais em Quick Sort: sem limite de profundidade ou troca para algoritmo iterativo, Quick Sort em listas patológicas pode estourar a stack (StackOverflowError em Java, RecursionError em Python). Implementações robustas usam IntroSort ou convertem para iterativo após certo nível.
4. Ordenar dados que já chegam ordenados do banco: aplicações que aplicam sort() no client-side em arrays já trazidos com ORDER BY do MySQL desperdiçam ciclos de CPU. O banco já ordenou de forma muito mais eficiente usando índices.
5. Comparar tipos misturados: em JavaScript, [10, 1, 2].sort() retorna [1, 10, 2] porque a comparação padrão é lexicográfica (string). Esquecer de passar a função comparadora (a, b) => a - b gera resultados visivelmente errados em produção.
6. Usar ordenação quando uma estrutura de dados ordenada resolveria: se inserções e ordenação acontecem o tempo todo, manter os dados em uma estrutura como TreeMap, Sorted Set (Redis) ou heap binário evita reordenar a cada operação, levando o custo amortizado de O(n log n) para O(log n) por inserção.
7. Não considerar ordenação externa para arquivos gigantes: tentar carregar 50 GB de logs em memória para ordenar quebra qualquer servidor. A solução correta envolve Merge Sort externo: dividir em chunks que cabem na RAM, ordenar cada chunk em disco e mesclar.

Algoritmo de Ordenação e a Shiftmind
A escolha e a aplicação correta de algoritmos de ordenação são fundamentais em projetos de software corporativo, especialmente em sistemas que lidam com grandes volumes de dados. Na Shiftmind, oferecemos serviços de criação de sites WordPress e desenvolvimento WordPress sob medida, considerando desde a arquitetura de banco de dados até a otimização de queries com índices apropriados, garantindo que ordenações em listas de produtos, posts e usuários respondam com performance adequada mesmo em grande escala.
Para empresas industriais e B2B, atuamos com e-commerce B2B, plataformas que frequentemente lidam com catálogos de dezenas de milhares de SKUs e exigem ordenações dinâmicas por preço, disponibilidade e relevância. Combinamos isso com estratégias de marketing digital B2B para garantir que a tecnologia bem aplicada se traduza em resultado comercial. E para manter tudo funcionando com estabilidade e performance contínua, oferecemos suporte e manutenção especializado, incluindo análise de queries lentas, reindexação de tabelas e otimização de ordenações em produção.
Termos relacionados
- Algoritmo
- Algoritmo de Busca
- Abstração
- Acoplamento
- ActiveRecord
- Agile (Metodologia Ágil)
- AJAX
- API
- Heap Sort
- Insertion Sort
- Selection Sort
- TimSort
- Radix Sort
- Big O
Conclusão
Algoritmos de ordenação são ferramentas indispensáveis no arsenal de qualquer desenvolvedor sério. A diferença entre uma aplicação rápida e uma lenta muitas vezes está na escolha correta entre Quick Sort, Merge Sort, TimSort ou abordagens híbridas — e em saber quando delegar a ordenação para a camada de banco de dados em vez de processá-la na aplicação. Conhecer Big O, estabilidade, uso de memória e os trade-offs de cada algoritmo é o que separa código que escala de código que quebra na primeira carga real.
Precisa de ajuda para construir aplicações WordPress, e-commerces B2B ou sistemas corporativos com performance e arquitetura sólida? A Shiftmind transforma necessidades técnicas complexas em soluções funcionais e otimizadas. Entre em contato e converse com nosso time.
