

O Apache Kafka é uma plataforma distribuída de streaming de eventos, open source, projetada para processar trilhões de eventos por dia com baixa latência, alta vazão e tolerância a falhas. Funciona como um sistema de mensageria publish-subscribe baseado em logs imutáveis, permitindo que aplicações produzam, armazenem e consumam fluxos contínuos de dados em tempo real.
Criado em 2010 pela equipe de engenharia do LinkedIn (Jay Kreps, Neha Narkhede e Jun Rao) para resolver o problema de pipelines de dados fragmentados, o projeto foi doado em 2011 para a Apache Software Foundation. Hoje é a espinha dorsal de empresas como Netflix, Uber, Airbnb, Walmart, LinkedIn, PayPal e Spotify, que processam diariamente volumes que atingem dezenas de trilhões de mensagens por meio de clusters Kafka.
Diferente de filas tradicionais, o Kafka persiste cada mensagem em disco por um período configurável (retention policy), o que permite que múltiplos consumidores leiam o mesmo dado em momentos diferentes, recomputem estados e construam pipelines de dados desacoplados entre microsserviços, sistemas analíticos e aplicações de machine learning.

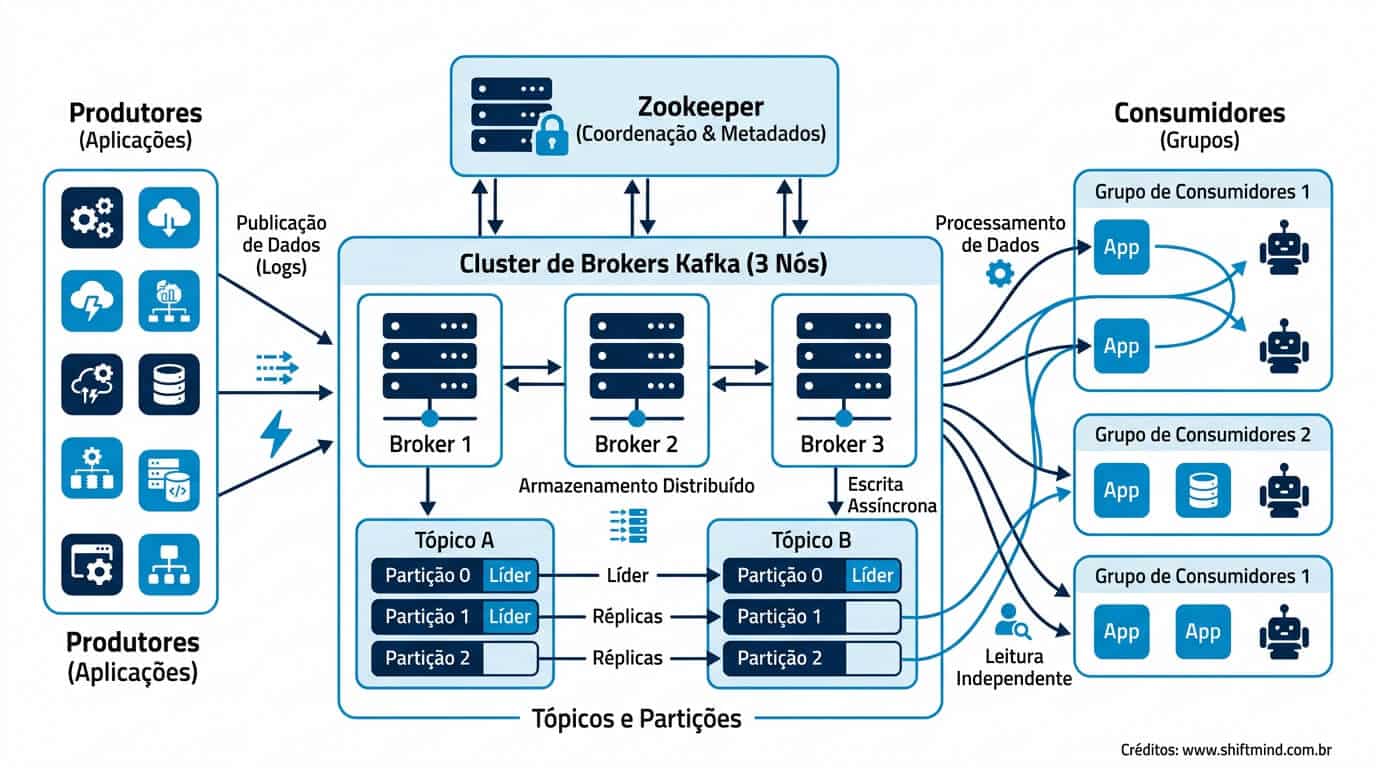
Como funciona o Apache Kafka?
A arquitetura do Kafka é construída sobre o conceito de log distribuído e imutável. Cada mensagem produzida é anexada ao final de um log persistido em disco, recebe um identificador sequencial chamado offset e fica disponível para qualquer consumidor que tenha permissão de leitura. Esse modelo simples permite throughput extremamente elevado — clusters Kafka bem dimensionados sustentam milhões de mensagens por segundo por broker.
Producer
O producer é a aplicação responsável por publicar mensagens em um tópico específico. Ele pode escolher a partition de destino manualmente, distribuir as mensagens via round-robin ou utilizar uma chave (key) que é hasheada para garantir que registros relacionados caiam sempre na mesma partition. Producers oferecem três níveis de garantia de entrega: at-most-once (acks=0, máxima performance), at-least-once (acks=1 ou all, padrão na maioria dos cenários) e exactly-once (com idempotência ativada e transações).
Consumer
O consumer assina um ou mais tópicos e processa mensagens em ordem dentro de cada partition. Consumers se organizam em consumer groups, e o Kafka distribui automaticamente as partitions entre os membros do grupo, garantindo paralelismo. Cada consumer mantém seu próprio offset, que pode ser commitado automaticamente ou manualmente, dando controle total sobre a semântica de processamento.
Broker
O broker é o servidor Kafka propriamente dito. Um cluster típico em produção tem entre 3 e 12 brokers, e cada broker armazena partitions de múltiplos tópicos. Quando um broker cai, as partitions que ele liderava são automaticamente reassignadas para réplicas em outros brokers, garantindo continuidade. Em deployments modernos, o KRaft (Kafka Raft) substitui o Zookeeper para coordenação de metadados, simplificando operação e melhorando escalabilidade.

Topics
O topic é a categoria lógica que agrupa mensagens relacionadas — equivalente a uma tabela em um banco de dados relacional. Um sistema de e-commerce, por exemplo, pode ter tópicos como pedidos-criados, pagamentos-aprovados, estoque-atualizado e emails-disparados. Cada tópico é dividido em partitions e configurado com políticas de retenção (por tempo ou tamanho) e número de réplicas.
Partitions
Partitions são a unidade de paralelismo do Kafka. Um tópico com 12 partitions pode ser processado por até 12 consumers simultaneamente dentro de um mesmo consumer group. A escolha do número de partitions é uma decisão arquitetural crítica: poucas partitions limitam vazão; muitas aumentam overhead de metadados e tempo de rebalance. A regra prática é estimar o throughput desejado dividido pelo throughput por partition (geralmente 10 a 50 MB/s).
Offset
O offset é o número sequencial atribuído a cada mensagem dentro de uma partition. É o ponteiro que o consumer mantém para saber até onde já processou. O Kafka armazena offsets em um tópico interno chamado __consumer_offsets, permitindo que consumers reiniciem e retomem do último ponto processado, ou voltem no tempo (replay) para reprocessar dados — recurso fundamental para event sourcing e correção de bugs em produção.
Para que serve o Kafka?
O Kafka resolve quatro classes principais de problemas em arquiteturas modernas: event streaming, comunicação assíncrona entre microsserviços, agregação de logs e analytics em tempo real.
Em event streaming, o Kafka atua como o sistema nervoso central da aplicação, capturando cada mudança de estado relevante (pedido criado, usuário cadastrado, sensor disparado) e disponibilizando esses eventos para qualquer consumidor interessado. Esse padrão é a base de event-driven architectures e event sourcing, onde o histórico completo de eventos é a fonte da verdade.

Em microsserviços, o Kafka substitui chamadas síncronas REST entre serviços por publicação de eventos, eliminando acoplamento temporal. Quando o serviço de pedidos publica um evento pedido-criado, os serviços de estoque, faturamento e notificação consomem assincronamente, cada um no seu ritmo, sem que o serviço de pedidos precise saber quem está ouvindo.
Em log aggregation, o Kafka centraliza logs de centenas de servidores e aplicações em um pipeline unificado, alimentando ferramentas como Elasticsearch, ClickHouse ou data lakes. Empresas como Netflix processam mais de 1 trilhão de eventos por dia em Kafka apenas para observabilidade e telemetria.
Em real-time analytics, o Kafka alimenta motores de processamento de stream como Apache Flink, Apache Spark Structured Streaming e Kafka Streams, permitindo dashboards atualizados em segundos, detecção de fraudes em tempo real e personalização dinâmica de experiência do usuário.
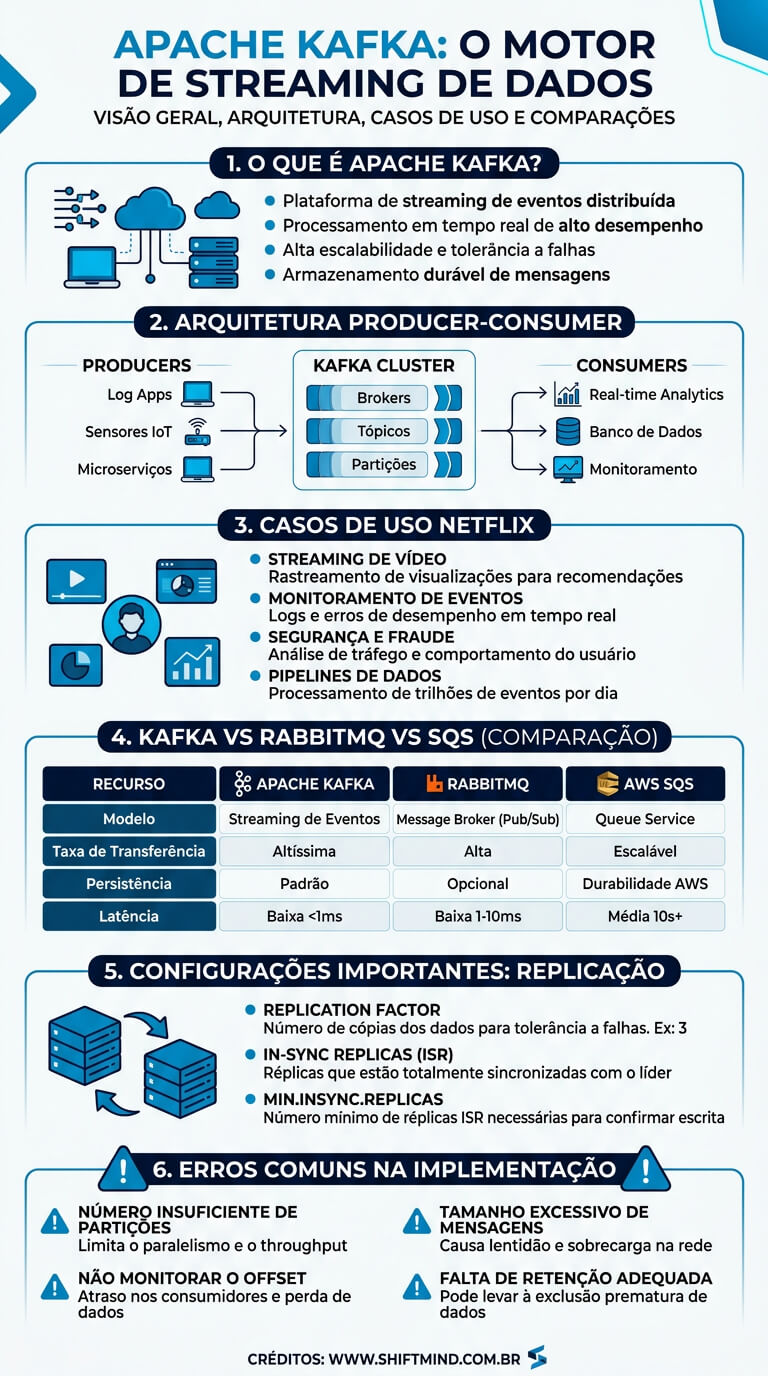
Casos de uso na prática
E-commerce com tracking comportamental
Um marketplace brasileiro de médio porte processa picos de 50 mil eventos por segundo durante a Black Friday: cliques em produtos, adições ao carrinho, abandonos, conclusões de compra, avaliações. Esses eventos são publicados em tópicos Kafka e consumidos simultaneamente por: (1) o motor de recomendação que recalcula afinidades em tempo real, (2) o sistema de remarketing que dispara emails para carrinhos abandonados, (3) o data warehouse via Kafka Connect para análise histórica e (4) o sistema de detecção de fraude que identifica padrões anômalos. Sem Kafka, cada uma dessas integrações seria um pipeline frágil e acoplado.

Microsserviços B2B em fintech
Uma fintech de antecipação de recebíveis no Brasil migrou de uma arquitetura monolítica para 40+ microsserviços usando Kafka como backbone de comunicação. O fluxo de aprovação de crédito, que antes era uma transação síncrona de 8 segundos, virou um pipeline assíncrono: o serviço de onboarding publica cliente-cadastrado, o motor de scoring consome e publica scoring-calculado, o serviço de limite consome e publica limite-aprovado, e assim por diante. O cliente recebe a resposta via webhook quando o pipeline conclui. Resultado: capacidade de processar 10x mais solicitações com a mesma infraestrutura e isolamento de falhas — se o motor de scoring cair, as solicitações ficam acumuladas no tópico aguardando, sem perda.
Integração de sistemas legados via CDC
Uma indústria de bens de consumo usa Kafka com Debezium (Change Data Capture) para sincronizar um ERP legado em Oracle com sistemas modernos de analytics, e-commerce B2B e CRM. Cada INSERT, UPDATE ou DELETE no Oracle é capturado pelo Debezium, publicado no Kafka e consumido pelos sistemas downstream. Isso permitiu modernizar a stack sem reescrever o ERP, eliminou ETLs noturnos e reduziu a latência de dados do varejo (de 24h para menos de 1 minuto entre venda e visibilidade no dashboard executivo).
Kafka vs RabbitMQ vs SQS
A escolha entre Kafka, RabbitMQ e Amazon SQS depende do padrão de uso, volume e garantias necessárias. Os três são sistemas de mensageria, mas com filosofias diferentes.
O RabbitMQ é um broker tradicional baseado no protocolo AMQP, otimizado para roteamento complexo de mensagens (exchanges, bindings, routing keys). Mensagens são tipicamente removidas após consumo, e o foco é entrega confiável de tarefas a workers. Excelente para filas de jobs, RPC assíncrono e cenários com poucos consumers e roteamento sofisticado. Throughput típico: dezenas de milhares de mensagens por segundo por nó.
O Apache Kafka é um log distribuído otimizado para alto throughput e múltiplos consumidores lendo o mesmo dado. Mensagens persistem por dias ou semanas, permitindo replay. Ideal para event streaming, pipelines de dados e arquiteturas event-driven em larga escala. Throughput típico: centenas de milhares a milhões de mensagens por segundo por broker.
O Amazon SQS é um serviço gerenciado de filas, simples e elástico, sem necessidade de gerenciar infraestrutura. Suporta filas standard (at-least-once, ordem não garantida) e FIFO (exactly-once, ordem garantida, limite de 3.000 msg/s por grupo). Ideal para times pequenos que querem terceirizar operação e não precisam de replay ou throughput extremo.
Resumindo a decisão: escolha RabbitMQ se precisar de roteamento complexo e baixo volume; Kafka se tiver alto volume, múltiplos consumidores e necessidade de replay; SQS se quiser simplicidade operacional e estiver totalmente na AWS.
Vantagens e desvantagens do Kafka
Vantagens:
- Throughput excepcional: capaz de processar milhões de mensagens por segundo com hardware comum.
- Durabilidade: mensagens persistidas em disco com replicação configurável, permitindo recuperação de falhas.
- Replay de eventos: consumers podem reprocessar dados a partir de qualquer offset, fundamental para event sourcing.
- Desacoplamento total: producers e consumers não se conhecem, evoluindo de forma independente.
- Ecossistema maduro: Kafka Connect, Kafka Streams, ksqlDB, Schema Registry e centenas de connectors prontos.
- Escalabilidade horizontal: adicionar brokers e partitions aumenta capacidade linearmente.
Desvantagens:
- Complexidade operacional: exige conhecimento de tuning, monitoramento e troubleshooting que poucos times dominam.
- Custo de infraestrutura: clusters em produção exigem múltiplos brokers, discos rápidos (SSD/NVMe) e rede de baixa latência.
- Curva de aprendizado: conceitos como partitions, offsets, consumer groups e rebalancing levam tempo para serem dominados.
- Não é a melhor escolha para baixo volume: em cenários com poucas mensagens por segundo, o overhead operacional não compensa.
- Roteamento simples: não suporta padrões complexos de roteamento como o RabbitMQ — toda lógica de filtragem precisa estar no consumer.
Erros comuns ao usar Kafka
Mesmo equipes experientes cometem deslizes recorrentes que comprometem performance, custo e confiabilidade. Os principais são:

- Configuração inadequada de partitions: criar tópicos com 1 ou 2 partitions limita o paralelismo permanentemente — aumentar partitions depois exige rebalance e quebra a ordenação por chave. Estime o throughput de pico e dimensione com folga (geralmente entre 6 e 30 partitions para tópicos de alto volume).
- Retention policy mal configurada: deixar o padrão de 7 dias em tópicos de alto volume sem dimensionar disco gera quebras em produção. Tópicos de auditoria podem precisar de retenção infinita (compactação por chave); tópicos transacionais podem viver com 24h.
- Ignorar consumer lag: não monitorar a diferença entre o último offset produzido e o último consumido leva a backlogs invisíveis que explodem em produção. Ferramentas como Burrow, Kafka Lag Exporter e Confluent Control Center são essenciais.
- Não usar Schema Registry: publicar JSON sem schema versionado leva a quebras silenciosas quando producers e consumers evoluem em ritmos diferentes. Avro, Protobuf ou JSON Schema com Schema Registry previnem incompatibilidades em runtime.
- Replication factor de 1 em produção: tópicos sem réplicas perdem dados quando um broker falha. O mínimo recomendado é replication.factor=3 com min.insync.replicas=2, garantindo durabilidade mesmo com 1 broker fora.
- Mensagens muito grandes: publicar payloads de megabytes em vez de referências (ex.: salvar arquivo no S3 e publicar apenas o caminho) sobrecarrega brokers e aumenta latência. O limite padrão é 1 MB por mensagem por boas razões.
- Acks=1 em cenários críticos: usar acks=1 (default) significa que o leader confirma antes de replicar — uma falha do leader nesse instante perde a mensagem. Para dados financeiros e auditáveis, use acks=all.
Apache Kafka e a Shiftmind
Implementar e operar Apache Kafka em produção exige infraestrutura robusta, baixa latência de rede e equipe especializada para tuning contínuo. A Shiftmind oferece a base de hospedagem e suporte que sustenta arquiteturas de streaming de eventos confiáveis.
Para clusters Kafka self-hosted que exigem CPUs dedicadas, discos NVMe e isolamento de recursos, nosso servidor dedicado oferece o controle total necessário para dimensionar brokers, ajustar parâmetros de kernel e garantir performance previsível. Para aplicações que consomem eventos Kafka e precisam servir conteúdo dinâmico, nossa hospedagem WordPress e a hospedagem gerenciada oferecem ambientes otimizados para alta disponibilidade.
O suporte e manutenção da Shiftmind acompanha desde o monitoramento de consumer lag até a configuração de retention policies adequadas ao seu negócio. Para operações de e-commerce B2B que exigem integração em tempo real entre ERP, CRM, marketplace e sistemas analíticos, projetamos pipelines de eventos que sustentam picos sazonais sem perda de dados.
Termos relacionados
- ACL (Access Control List) — controle de permissões em tópicos Kafka
- Active Directory — integração de autenticação corporativa com clusters Kafka
- Alta Disponibilidade (High Availability) — requisito fundamental para clusters Kafka em produção
- Afinidade de Sessão (Session Affinity) — relacionada ao roteamento de mensagens por chave
- AMD EPYC — processadores recomendados para brokers de alta vazão
- Ansible — automação de provisionamento de clusters Kafka
- RabbitMQ — broker AMQP alternativo para mensageria
- AWS SQS — serviço gerenciado de filas da Amazon
- Pub/Sub — padrão de comunicação publish-subscribe
- Microsserviços — arquitetura que se beneficia de Kafka como backbone
- Event Sourcing — padrão arquitetural baseado em log de eventos
- Apache Spark — engine de processamento batch e stream sobre Kafka
- Apache Flink — engine de processamento de stream com baixa latência
- Zookeeper — coordenador de metadados (substituído pelo KRaft em versões recentes)
Conclusão
O Apache Kafka deixou de ser uma curiosidade de empresas como LinkedIn e Netflix para se tornar infraestrutura crítica em qualquer arquitetura distribuída séria. Seu modelo de log imutável, com replay, alto throughput e desacoplamento total entre producers e consumers, mudou a forma como sistemas modernos compartilham dados — substituindo integrações ponto-a-ponto frágeis por um backbone unificado de eventos.
Adotar Kafka, no entanto, não é decisão trivial. Exige investimento em infraestrutura, capacitação da equipe e maturidade operacional. Para volumes baixos ou times sem experiência em sistemas distribuídos, alternativas como RabbitMQ ou SQS podem ser mais adequadas. Mas para empresas que precisam processar eventos em escala, integrar dezenas de sistemas e construir pipelines de dados resilientes, Kafka é o padrão de fato do mercado.

Sua empresa precisa de uma infraestrutura preparada para sustentar Apache Kafka em produção? A Shiftmind oferece servidores dedicados, hospedagem gerenciada e suporte especializado para pipelines de streaming de eventos. Fale com nossos especialistas e descubra como estruturar uma arquitetura event-driven robusta para o seu negócio.
