
Apache Spark é um motor de processamento distribuído de código aberto projetado para análise de grandes volumes de dados em clusters de máquinas, oferecendo velocidade até 100 vezes superior ao Hadoop MapReduce em workloads que cabem em memória. Criado em 2009 no AMPLab da UC Berkeley e mantido pela Apache Software Foundation desde 2013, o Spark se consolidou como a espinha dorsal de pipelines de big data, machine learning e analytics em empresas como Netflix, Uber, Airbnb, Alibaba e Tencent.
O diferencial do Spark está na combinação de processamento em memória, abstrações de alto nível (DataFrames e Datasets) e uma stack unificada que cobre ETL em lote, streaming, SQL interativo, machine learning e processamento de grafos — tudo sob a mesma API e o mesmo runtime. Em vez de manter ferramentas separadas para cada caso de uso, equipes de engenharia de dados conseguem padronizar a infraestrutura analítica em torno de um único framework.
Como funciona o Apache Spark?
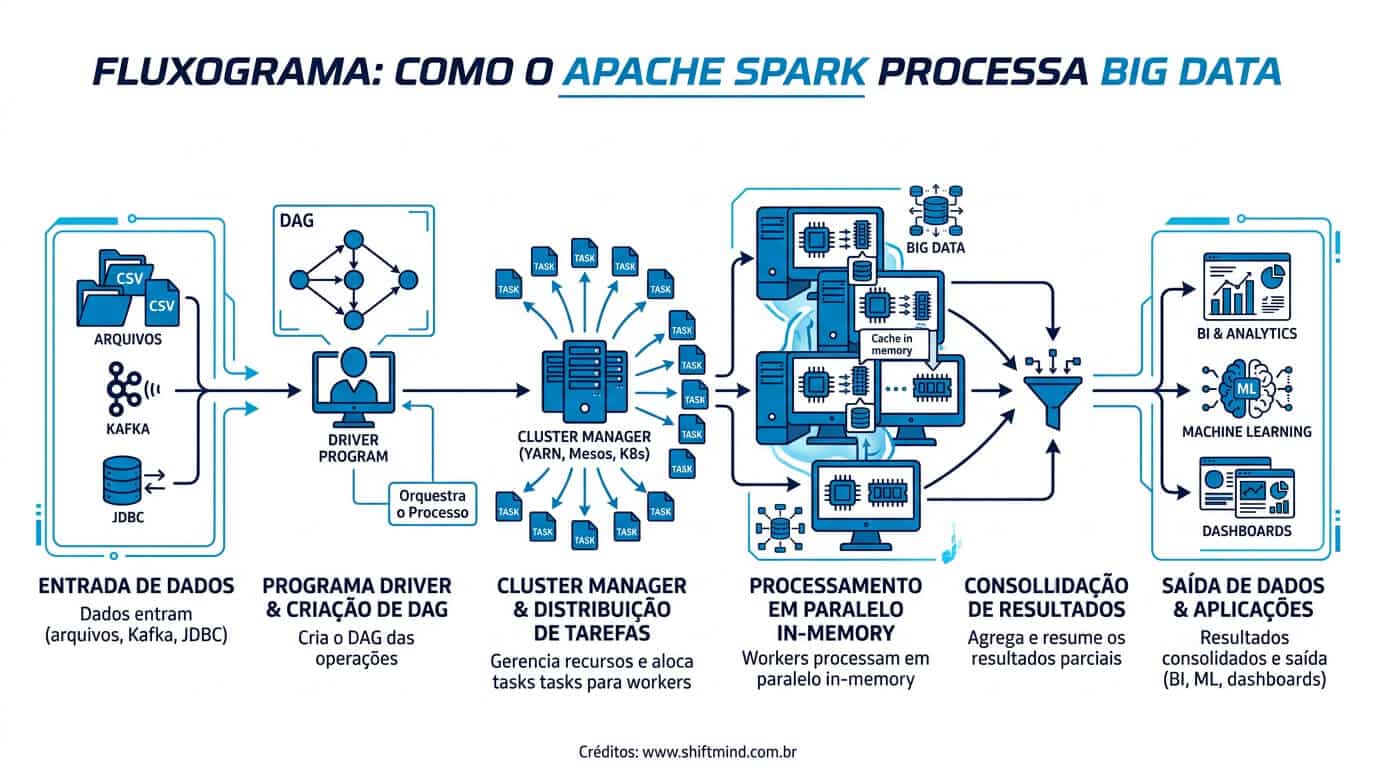
O Spark organiza o processamento em torno de um driver program que coordena a execução e múltiplos executors que rodam tarefas em paralelo nos nós do cluster. Para entender o funcionamento na prática, é preciso compreender quatro pilares: a arquitetura distribuída, as abstrações de dados (RDD e DataFrames), o modelo de lazy evaluation e o uso intensivo de memória.

Arquitetura distribuída
Um cluster Spark é composto por um driver, um cluster manager (Standalone, YARN, Mesos ou Kubernetes) e múltiplos worker nodes que hospedam executors. O driver mantém o SparkContext, divide o trabalho em stages e tasks, e envia esses jobs aos executors. Cada executor é um processo JVM responsável por rodar tarefas e armazenar partições de dados em memória ou disco. Essa separação permite escalar horizontalmente de algumas máquinas para milhares de nós sem mudar a aplicação.
RDD e DataFrames
A abstração original do Spark é o RDD (Resilient Distributed Dataset), uma coleção imutável e particionada de objetos que pode ser processada em paralelo. RDDs oferecem tolerância a falhas através do lineage: o Spark registra a sequência de transformações aplicadas e consegue recomputar partições perdidas a partir dos dados originais, sem precisar replicar tudo no disco. A partir do Spark 1.3, os DataFrames trouxeram uma API tabular inspirada em pandas e SQL, com schema explícito e otimizações automáticas via Catalyst Optimizer. Já os Datasets (Spark 1.6+) unificam type-safety de RDDs com a eficiência dos DataFrames em Scala e Java.
Lazy evaluation
Transformações no Spark (map, filter, join, groupBy) não disparam computação imediata — elas constroem um grafo lógico de operações. O processamento só acontece quando uma action é chamada (count, collect, save, show). Esse modelo lazy permite que o Catalyst reordene, combine ou elimine etapas antes de executar, gerando planos físicos otimizados. Por exemplo, um filter aplicado depois de um join pode ser empurrado para antes do join (predicate pushdown), reduzindo drasticamente o volume embaralhado entre nós.
In-memory computing
O ganho de performance do Spark sobre o MapReduce vem principalmente do uso de memória RAM para resultados intermediários. Enquanto o MapReduce grava cada estágio no disco, o Spark mantém DataFrames cacheados em memória entre operações iterativas — algoritmo de PageRank, regressão logística, K-means e demais cargas iterativas se beneficiam desse modelo. Benchmarks publicados pela Databricks mostram speedups de 10x a 100x sobre Hadoop em cenários iterativos, e ganhos consistentes de 2x a 10x em workloads de ETL puro.

Para que serve o Spark?
O Spark é uma plataforma multipropósito que cobre praticamente todo o ciclo de vida de dados em escala. Os casos de uso mais comuns são:
- ETL e ELT em larga escala: ler dados brutos de fontes heterogêneas (S3, HDFS, Kafka, bancos relacionais), aplicar transformações de limpeza, deduplicação e enriquecimento, e carregar em data lakes ou data warehouses. A Netflix processa diariamente mais de 1 trilhão de eventos com pipelines Spark.
- Machine learning em escala: via MLlib, é possível treinar modelos de classificação, regressão, clustering e sistemas de recomendação sobre datasets que não caberiam em uma única máquina. O Uber usa Spark para alimentar pipelines de feature engineering do Michelangelo, sua plataforma interna de ML.
- Processamento de streaming: Structured Streaming permite consumir tópicos Kafka, Kinesis ou sockets TCP com a mesma API dos DataFrames batch, garantindo exactly-once semantics. Casos de detecção de fraude, monitoramento de IoT e analytics em tempo real rodam sobre essa stack.
- Analytics interativo via SQL: Spark SQL permite consultar petabytes de dados com sintaxe ANSI SQL padrão, conectando-se a BI tools via JDBC/ODBC. O Airbnb mantém centenas de analistas executando queries ad-hoc sobre seu data lake usando Spark.
- Processamento de grafos: GraphX e GraphFrames habilitam algoritmos como PageRank, connected components e shortest path sobre redes sociais e grafos de conhecimento.
Componentes principais
O Spark é estruturado como uma stack modular sobre um núcleo comum. Os três componentes mais utilizados em produção são Spark Core, Spark SQL e a dupla Spark Streaming + MLlib.
Spark Core
É a fundação do framework: gerencia a execução de tarefas, agendamento, recuperação de falhas, comunicação entre nós e operações básicas sobre RDDs. Toda funcionalidade dos demais módulos depende do Core. Aqui também moram o gerenciamento de memória, o sistema de broadcast variables (variáveis read-only distribuídas eficientemente) e os accumulators (contadores agregáveis em paralelo).
Spark SQL
Permite executar SQL e manipular DataFrames sobre dados estruturados e semiestruturados (Parquet, ORC, JSON, Avro, CSV, Delta Lake). O Catalyst Optimizer analisa cada query, aplica regras de otimização baseadas em custo e gera bytecode JVM otimizado via projeto Tungsten. Spark SQL é o módulo mais usado em ambientes corporativos justamente porque preserva a familiaridade do SQL para analistas e cientistas de dados.
Spark Streaming e MLlib
Spark Streaming (e seu sucessor Structured Streaming) processa fluxos contínuos em micro-batches ou modo contínuo, suportando janelas temporais, watermarks para dados atrasados e checkpointing para tolerância a falhas. Já a MLlib oferece implementações distribuídas de algoritmos clássicos: regressão linear e logística, árvores de decisão, random forest, gradient-boosted trees, K-means, ALS para recomendação, além de utilitários de feature engineering como TF-IDF, Word2Vec e StandardScaler.

Spark vs Hadoop MapReduce
A comparação entre Spark e Hadoop MapReduce ainda gera dúvidas, sobretudo em empresas migrando data lakes legados. As diferenças relevantes são:
- Modelo de execução: MapReduce escreve cada estágio intermediário no HDFS, gerando I/O massivo. O Spark mantém dados em memória entre estágios sempre que possível, eliminando essa serialização.
- Performance: em workloads iterativos (ML, grafos), o Spark é tipicamente 10x a 100x mais rápido. Em ETL batch simples, o ganho fica entre 2x e 5x.
- APIs: MapReduce expõe apenas as funções map e reduce, exigindo código verboso. O Spark oferece dezenas de operadores (filter, join, groupBy, window, pivot) em Scala, Python, Java, R e SQL.
- Latência: MapReduce é exclusivamente batch, com jobs que iniciam em segundos a minutos. O Spark suporta queries interativas e streaming com latência subsegundo via Structured Streaming.
- Ecossistema: ambos rodam sobre o HDFS e podem coexistir no YARN, mas o Spark se integra nativamente a Kafka, Cassandra, Elasticsearch, Delta Lake, Iceberg e Hudi.
Na prática, MapReduce permanece relevante apenas em pipelines legados ou workloads I/O-bound muito grandes onde a memória do cluster é limitada. Para projetos novos, o Spark é o padrão de mercado.
Linguagens suportadas
O Spark oferece APIs nativas em quatro linguagens, atendendo perfis diferentes de equipe:
- Scala: linguagem original do Spark e historicamente a mais performática, já que o engine roda na JVM e Scala compila para bytecode sem overhead de tradução. Recomendada para times de engenharia de dados que precisam de máxima performance e type-safety com Datasets.
- Python (PySpark): de longe a API mais popular hoje, especialmente em times de data science. Versões recentes do PySpark eliminaram boa parte do gap de performance via Arrow-based serialization e vectorized UDFs (pandas UDFs).
- Java: totalmente suportado, mas sintaxe verbosa torna o desenvolvimento mais lento. Usado principalmente em empresas com forte padronização em Java.
- R (SparkR e sparklyr): permite a estatísticos e analistas usarem dplyr-style syntax sobre clusters Spark. Cobertura de funcionalidades é menor que Scala e Python.
Para projetos novos, a recomendação geral é PySpark para times mistos de dados/ML e Scala quando performance crítica e type-safety justificarem a curva de aprendizado.
Erros comuns ao usar Spark
Apesar das abstrações de alto nível, o Spark exige entendimento do modelo distribuído para evitar armadilhas que destroem performance. Os erros mais frequentes são:

- Data skew (distribuição desigual): quando uma chave de join ou groupBy concentra a maioria dos registros, uma única partição recebe carga desproporcional e o job trava esperando esse executor. Mitigação: salting de chaves, broadcast joins para tabelas pequenas, ou skew hints no Spark 3.x.
- OutOfMemoryError (OOM): ocorre quando uma partição não cabe na memória do executor, normalmente após shuffles agressivos ou collects mal dimensionados. Aumentar spark.executor.memory ajuda, mas a solução real é controlar particionamento e evitar collect() em datasets grandes.
- Particionamento inadequado: partições muito grandes (acima de algumas centenas de MB) geram tasks lentas; muito pequenas causam overhead de scheduling. Regra prática: alvo de 100-200 MB por partição e múltiplo do número total de cores do cluster.
- Shuffles excessivos: operações como groupByKey, repartition e joins não otimizados forçam embaralhamento de dados entre nós pela rede — o gargalo mais caro do Spark. Preferir reduceByKey sobre groupByKey, usar broadcast joins quando uma das tabelas é pequena e cachear DataFrames reutilizados.
- Uso indevido de UDFs em Python: UDFs Python tradicionais quebram a otimização do Catalyst e serializam dados linha a linha entre JVM e Python, derrubando a performance. Substituir por funções nativas do Spark SQL ou pandas UDFs vetorizadas sempre que possível.
- Cache desnecessário: chamar cache() em DataFrames usados uma única vez consome memória sem benefício. Cachear apenas DataFrames reaproveitados em múltiplas ações.
Apache Spark e a Shiftmind
A Shiftmind ajuda empresas a transformar dados em vantagem competitiva integrando frameworks como Apache Spark a estratégias de marketing e tecnologia. Nossos times conectam pipelines de big data a iniciativas de marketing digital B2B, alimentando segmentações avançadas, lead scoring e personalização em escala. Para operações que dependem de catálogos extensos e transações complexas, nossa solução de e-commerce B2B integra-se a data lakes processados via Spark para entregar recomendações e relatórios em tempo real. Também oferecemos criação de sites WordPress e desenvolvimento WordPress sob medida para empresas que precisam de portais analíticos, dashboards executivos e integração com APIs de dados. Para garantir que toda essa infraestrutura permaneça estável e performática, contamos com serviço de suporte e manutenção contínuo, monitorando integrações, performance e segurança.
Termos relacionados
Para aprofundar o entendimento sobre o ecossistema do Apache Spark e tecnologias correlatas, confira os termos relacionados em nosso glossário:
- Abstração
- Acoplamento
- ActiveRecord
- Agile (Metodologia Ágil)
- AJAX
- Algoritmo
- Algoritmo de Busca
- Algoritmo de Ordenação
- Amazon Alexa SDK
- Android
- Android Studio
- Angular
- Anotação
- Anti-Pattern
- API
Conceitos complementares úteis no contexto do Spark incluem Hadoop, MapReduce, HDFS, Kafka, Scala, PySpark, Databricks, Big Data, Machine Learning e ETL — todos pilares de uma arquitetura analítica moderna.
Conclusão
Apache Spark se consolidou como o padrão de fato para processamento distribuído de big data graças à combinação rara de performance, expressividade de API e cobertura de casos de uso — do ETL clássico ao streaming, do SQL interativo ao machine learning. Empresas como Netflix, Uber e Airbnb operam plataformas inteiras sobre Spark porque ele entrega escala horizontal real, tolerância a falhas e uma curva de adoção razoável para times que já dominam SQL ou Python.
Para tirar proveito do framework é preciso ir além do tutorial inicial: dominar particionamento, shuffles, otimizações do Catalyst e os pitfalls de UDFs Python separa equipes que conseguem rodar workloads de produção de forma econômica daquelas que queimam orçamento em clusters mal dimensionados.

Quer estruturar pipelines de dados e marketing analytics com a robustez necessária para crescer em escala? A Shiftmind combina expertise técnica em big data, automação de marketing e desenvolvimento web para entregar plataformas integradas e auditáveis. Entre em contato e descubra como podemos acelerar sua estratégia de dados.
