

APM (Application Performance Monitoring), ou Monitoramento de Performance de Aplicações, é a disciplina de observar, medir e diagnosticar o comportamento de aplicações em produção em tempo real, capturando métricas de latência, throughput, taxa de erros e consumo de recursos para garantir que o software entregue a experiência esperada aos usuários finais. Diferente do monitoramento tradicional de infraestrutura, que se preocupa com CPU, memória e disco de servidores isolados, o APM correlaciona o desempenho do código da aplicação com a stack inteira, do navegador do usuário até a query SQL executada no banco de dados.
Em ambientes modernos baseados em microserviços, contêineres e arquiteturas distribuídas, o APM deixou de ser um diferencial técnico para se tornar uma exigência operacional. Segundo pesquisa da Gartner, 60% das empresas que dependem de aplicações críticas adotam alguma ferramenta de APM, e o mercado global da categoria deve ultrapassar US$ 13 bilhões até 2027. O motivo é simples: o custo médio de uma hora de downtime em aplicações corporativas chega a US$ 300 mil, segundo levantamento da ITIC, e pode passar de US$ 1 milhão para grandes e-commerces durante picos de venda.
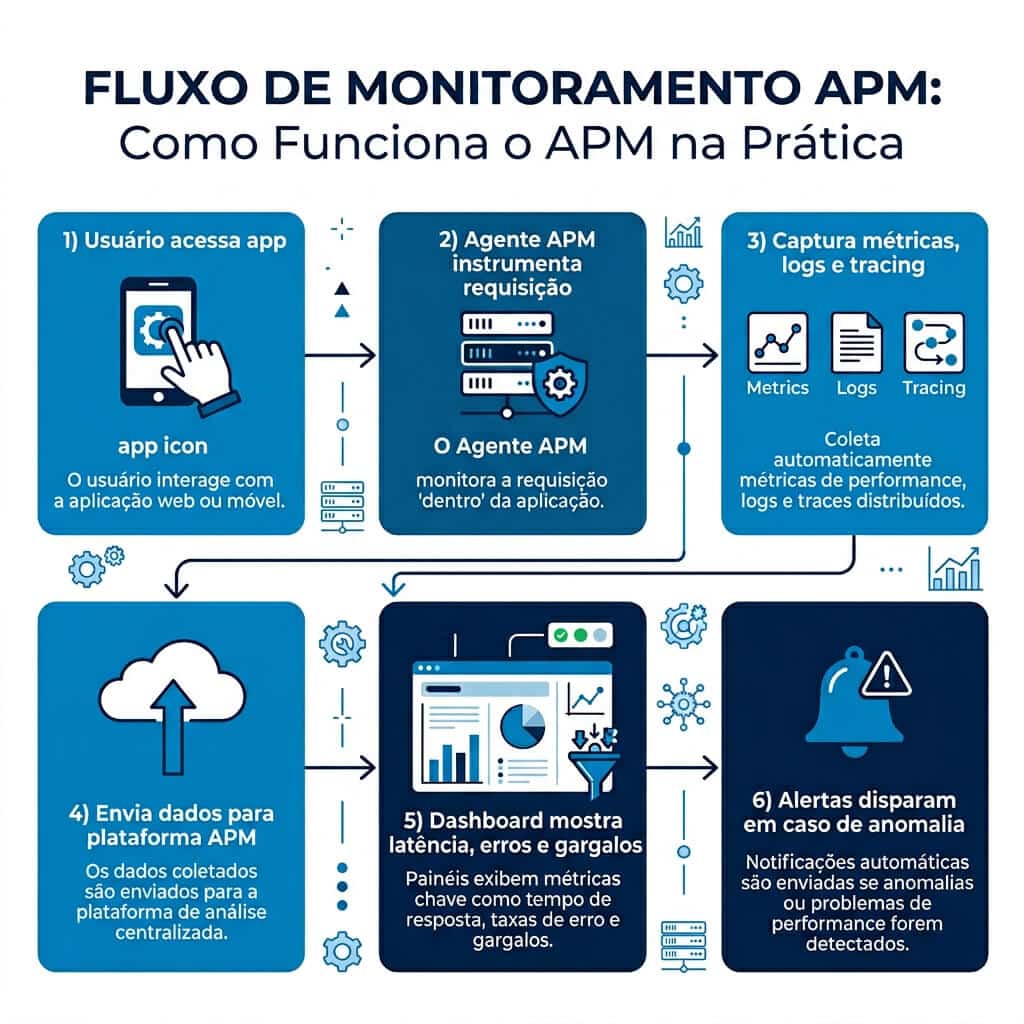
Como funciona o APM?
O APM combina coleta automática de dados, agregação em tempo real e visualização contextualizada para transformar bilhões de eventos em insights acionáveis. A maior parte das ferramentas modernas opera através de quatro pilares técnicos que trabalham de forma integrada.

Instrumentação
A instrumentação é o ponto de partida do APM. Consiste em injetar código de coleta dentro da aplicação para capturar eventos de execução. Existem duas abordagens principais: instrumentação automática, na qual um agente nativo da linguagem (PHP, Node.js, Java, Python, .NET) intercepta chamadas de função sem alteração no código-fonte; e instrumentação manual, na qual o desenvolvedor adiciona marcadores customizados para medir trechos específicos de negócio. Ferramentas como New Relic e Datadog oferecem agentes que se acoplam ao runtime e começam a coletar dados em minutos.
Tracing distribuído
O tracing distribuído rastreia uma requisição do início ao fim, mesmo quando ela atravessa dezenas de serviços diferentes. Cada operação recebe um identificador único (trace ID) propagado por headers HTTP, mensagens de fila e chamadas RPC. O resultado é uma visualização em cascata mostrando exatamente onde o tempo foi gasto: 120 ms no API Gateway, 45 ms no serviço de autenticação, 380 ms na query do banco, 90 ms no cache Redis. Sem tracing, identificar gargalos em arquiteturas distribuídas é praticamente impossível.
Métricas
As métricas são dados numéricos agregados em intervalos regulares: requisições por segundo, tempo médio de resposta, percentil 95 de latência, taxa de erros HTTP 5xx, uso de heap da JVM, número de conexões abertas no pool do banco. Métricas formam a base dos dashboards e dos alertas. O padrão de mercado é coletar métricas RED (Rate, Errors, Duration) para serviços de requisição-resposta e USE (Utilization, Saturation, Errors) para recursos de infraestrutura.
Logs
Os logs registram eventos discretos com contexto detalhado: stack traces de exceções, queries SQL executadas, payloads recebidos, decisões de roteamento. Quando integrados ao APM, os logs ficam correlacionados ao trace ID, permitindo que um engenheiro pule de uma latência anormal em um dashboard direto para as linhas exatas de log que detalham o que aconteceu naquela requisição específica.

Para que serve o APM?
O APM serve para detectar gargalos de performance antes que afetem o usuário final, reduzir o MTTR (Mean Time To Recovery) durante incidentes e melhorar continuamente a experiência percebida. Um e-commerce que descobre, via APM, que 8% das transações no checkout sofrem timeout por causa de uma query lenta no serviço de cálculo de frete consegue agir antes que a taxa de abandono cresça.
A redução de MTTR é um dos ganhos mais palpáveis. Sem APM, diagnosticar um problema em produção pode levar horas de investigação manual em logs espalhados por dezenas de servidores. Com APM, o engenheiro de plantão recebe um alerta detalhando o serviço afetado, abre o trace da requisição problemática e identifica a causa em minutos. Estudos da Forrester apontam reduções de MTTR de 50% a 70% em organizações maduras em observabilidade.
Além disso, o APM melhora a experiência do usuário ao mapear o desempenho real percebido no navegador ou no aplicativo móvel. Métricas como Largest Contentful Paint, First Input Delay e Cumulative Layout Shift, que compõem os Core Web Vitals do Google, são capturadas e correlacionadas a problemas de backend, conectando UX e infraestrutura em uma visão única.
Componentes monitorados
Uma plataforma de APM completa monitora três camadas que, juntas, formam a experiência ponta a ponta da aplicação.
Aplicação
Inclui o código que executa a lógica de negócio: controllers, services, jobs em background, integrações com APIs externas, ORM, cache. O APM mede tempo de execução por método, frequência de chamadas, exceções lançadas, queries N+1, falhas em chamadas externas e uso de threads. Em aplicações WordPress, por exemplo, o APM identifica plugins lentos, hooks excessivamente custosos e queries do wp_query que travam o carregamento de páginas.

Infraestrutura
Engloba servidores, contêineres, orquestradores, bancos de dados, brokers de mensagem e serviços de cache. O APM coleta métricas de CPU, memória, disco, rede, IOPS, conexões TCP e saturação de filas. Essa camada é essencial para correlacionar problemas de aplicação com limites de recurso: uma latência alta pode ser sintoma de saturação de CPU no nó Kubernetes que hospeda o serviço.
Experiência do usuário
É a camada mais externa, que mede o que o usuário realmente vive. Inclui Real User Monitoring (RUM), que captura tempos de carregamento em navegadores reais, e Synthetic Monitoring, que executa transações simuladas em intervalos regulares para detectar indisponibilidade. A experiência do usuário é o termômetro final: se um relatório mostra latência saudável no backend mas o RUM aponta páginas lentas, o problema pode estar no CDN, em scripts de terceiros ou no roteamento de DNS.
Principais ferramentas
O mercado de APM amadureceu rapidamente e hoje conta com plataformas robustas. As mais relevantes são:
- New Relic: pioneira na categoria, oferece APM, infrastructure, browser, mobile e logs em uma plataforma unificada. Modelo de cobrança por dados ingeridos e usuários ativos.
- Datadog: líder em observabilidade integrada, com mais de 600 integrações nativas. Forte em ambientes cloud-native e Kubernetes. Cobrança modular por host e por funcionalidade.
- Dynatrace: reconhecido pela tecnologia OneAgent, que descobre topologia automaticamente, e pelo Davis AI, que executa análise de causa raiz de forma autônoma. Posicionado para grandes corporações.
- AppDynamics: da Cisco, foco em mapeamento de transações de negócio e correlação com performance técnica. Forte em ambientes Java e .NET enterprise.
- Elastic APM: parte do Elastic Stack (antigo ELK), open source com versão comercial. Boa opção para times que já operam Elasticsearch e desejam unificar logs, métricas e traces na mesma plataforma.
Vantagens e desvantagens
O APM traz ganhos claros, mas exige decisões conscientes sobre custo, complexidade e governança.
Vantagens:

- Diagnóstico rápido de problemas em produção com correlação automática entre camadas;
- Redução significativa de MTTR e impacto financeiro de incidentes;
- Visibilidade de jornadas críticas de negócio (checkout, login, busca);
- Capacidade de detectar degradação gradual antes de quebrar SLOs;
- Base de dados para decisões de capacity planning e otimização de custos cloud.
Desvantagens:
- Custo elevado em ambientes de alto volume, especialmente em modelos baseados em dados ingeridos;
- Overhead de instrumentação pode adicionar 1% a 5% de latência se mal configurado;
- Curva de aprendizado para extrair valor real além de dashboards superficiais;
- Risco de vendor lock-in quando se depende de agentes proprietários;
- Necessidade de cultura de observabilidade — ferramenta sem processo gera mais ruído do que insight.
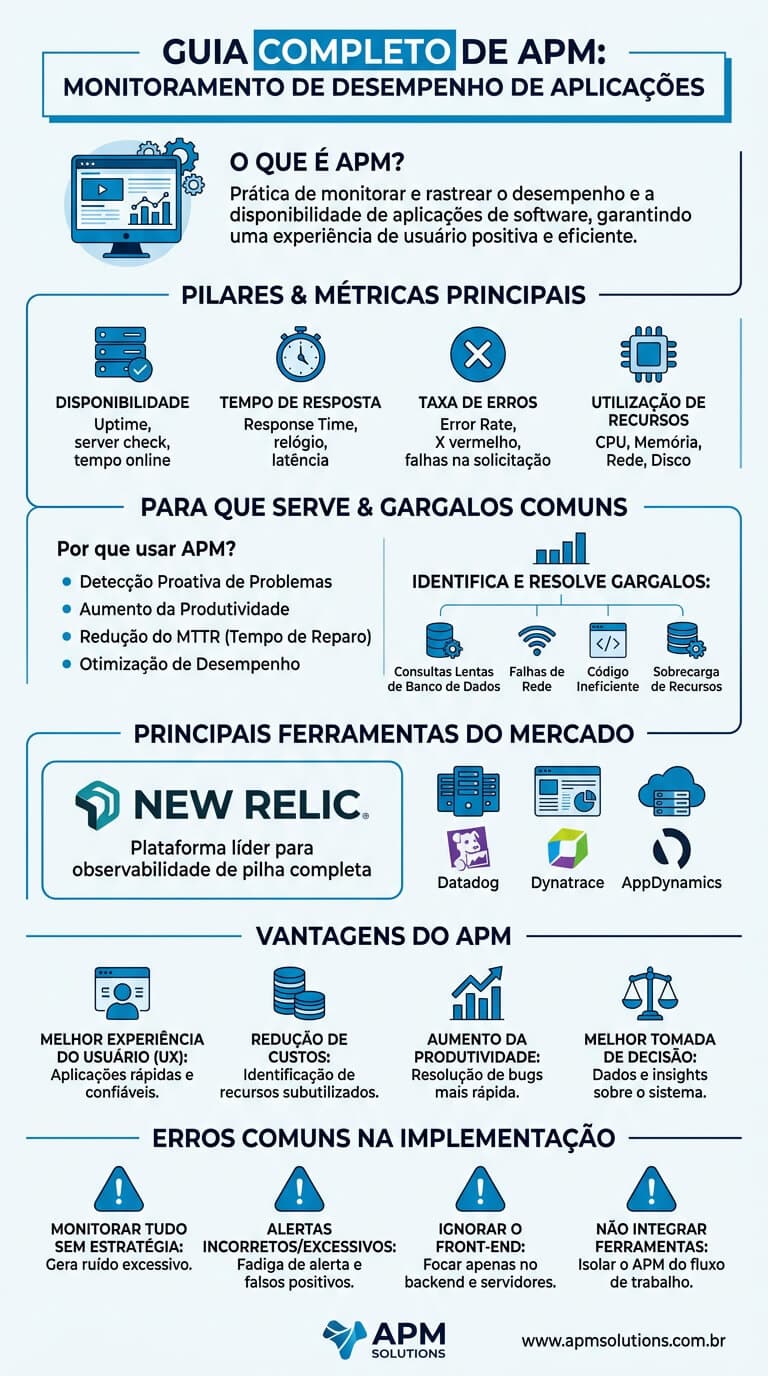
Erros comuns ao implementar APM
Implementar APM sem método transforma a ferramenta em fonte de frustração. Os erros mais frequentes que comprometem o retorno do investimento incluem:
- Configurar alertas demais: times que criam centenas de alertas sem priorização sofrem fadiga de alarme. Quando tudo é urgente, nada é. O ideal é começar com alertas baseados em SLOs e expandir gradualmente.
- Sampling errado: em sistemas de alto throughput, capturar 100% das requisições é inviável e caro. Mas amostragem mal calibrada (1% fixo, por exemplo) descarta exatamente os erros raros que mais precisam ser investigados. Sampling adaptativo, que prioriza traces de erro e latência alta, é a abordagem correta.
- Subestimar o custo de instrumentação: agentes proprietários cobram por dados ingeridos, e o volume cresce de forma não-linear com a complexidade do sistema. Sem governança, a fatura mensal pode triplicar em poucos meses sem que ninguém perceba até receber o boleto.
- Ignorar contexto de negócio: dashboards técnicos com gráficos de latência e CPU não comunicam nada para áreas de produto e operações. APM maduro vincula métricas técnicas a indicadores de negócio (carrinhos abandonados, pedidos perdidos, leads não capturados).
- Não revisar a instrumentação periodicamente: aplicações evoluem, novos serviços surgem, dependências mudam. Instrumentação que era boa há seis meses pode estar deixando lacunas críticas hoje. Revisão trimestral da cobertura de APM deve estar no calendário do time.
- Tratar APM como projeto e não como prática: instalar a ferramenta não basta. APM exige ritual contínuo de revisão de alertas, postmortems com traces como evidência, e cultura de observabilidade compartilhada entre dev e ops.
APM e a Shiftmind
Na Shiftmind, performance em produção é prioridade desde o primeiro deploy. Os clientes que operam projetos críticos em servidor dedicado contam com monitoramento ativo de aplicação e infraestrutura, com alertas configurados para detectar degradação antes que afete usuários finais. Em projetos de hospedagem WordPress, monitoramos tempo de resposta do PHP-FPM, queries lentas do MySQL e cache hit ratio do Redis para garantir páginas rápidas mesmo sob alto tráfego.
Para operações que exigem maior tranquilidade, a hospedagem gerenciada inclui APM básico embutido, com relatórios mensais de performance e identificação proativa de plugins problemáticos. O serviço de suporte e manutenção usa as métricas de APM para priorizar otimizações que entregam ganho real de velocidade, em vez de aplicar ajustes genéricos sem evidência. E a camada de segurança de websites se beneficia diretamente dos dados de APM para detectar padrões anômalos de tráfego que indicam tentativas de ataque ou exploração de vulnerabilidades.

Termos relacionados
- ACL (Access Control List)
- Active Directory
- Alta Disponibilidade (High Availability)
- Afinidade de Sessão (Session Affinity)
- AMD EPYC
- Ansible
- Apache
- Apache Kafka
- API Gateway
- Observability
- OpenTelemetry
- Tracing
- SLO (Service Level Objective)
- SLI (Service Level Indicator)
- Prometheus
- Grafana
Conclusão
APM deixou de ser uma camada opcional de monitoramento para se tornar a coluna vertebral da operação de qualquer aplicação que precisa entregar valor consistente em produção. Sem ele, times reagem a incidentes no escuro; com ele, decisões de engenharia, produto e infraestrutura passam a ser orientadas por dados reais sobre o que acontece quando o código encontra o usuário. A diferença entre ter APM e operar com APM bem implementado, no entanto, está na cultura: ferramenta sem método vira ruído, mas observabilidade madura vira vantagem competitiva.
Quer garantir que sua aplicação WordPress, e-commerce ou plataforma corporativa esteja rodando com a performance que seu negócio exige? A Shiftmind combina hospedagem otimizada, suporte técnico contínuo e monitoramento ativo para que você descubra problemas antes do seu cliente. Fale com nossa equipe e descubra como elevar a performance da sua aplicação a um novo patamar.
