

Algoritmo de busca é um procedimento computacional que localiza um elemento específico (ou confirma sua ausência) dentro de uma coleção de dados, retornando sua posição, valor ou referência. Ele é a base de praticamente todo sistema que precisa recuperar informação com eficiência: bancos de dados, motores de busca, indexadores, autocomplete, sistemas de roteamento e estruturas de cache.
A escolha do algoritmo correto impacta diretamente a performance da aplicação. Uma busca linear em um array de 10 milhões de registros pode levar segundos, enquanto uma busca binária no mesmo conjunto retorna em microssegundos. Entender os tipos disponíveis, suas complexidades (Big O) e quando aplicar cada um é fundamental para qualquer desenvolvedor que constrói sistemas escaláveis.
Neste artigo você vai aprender como funcionam os algoritmos de busca, conhecer os três principais tipos (linear, binária e em árvores/grafos), comparar suas complexidades em uma tabela Big O e descobrir os erros mais comuns que profissionais cometem ao implementá-los em ambientes de produção.

Como funciona um Algoritmo de Busca?
Um algoritmo de busca recebe como entrada uma coleção de dados e uma chave de busca (o valor que se quer encontrar). Ele percorre a coleção seguindo uma estratégia específica e retorna o índice, o registro ou um indicador de que o elemento não existe. A estratégia varia conforme a estrutura de dados subjacente: arrays, listas ligadas, árvores, grafos ou tabelas hash exigem abordagens diferentes.
O comportamento do algoritmo também depende de pré-condições: alguns exigem que os dados estejam ordenados, outros funcionam em qualquer ordem mas pagam o preço em desempenho. Existem ainda algoritmos que sacrificam memória por velocidade (como hash tables, que oferecem busca O(1) média mas consomem espaço adicional para a tabela).
Busca em estruturas lineares
Estruturas lineares como arrays e listas ligadas armazenam elementos em sequência. A busca linear percorre cada posição do início ao fim até encontrar o alvo ou esgotar a coleção. Para arrays ordenados, é possível aplicar busca binária, que divide o espaço de busca pela metade a cada iteração. A escolha depende da ordenação prévia dos dados e da frequência das operações.
Em listas ligadas, a busca binária não é eficiente porque o acesso aleatório a posições intermediárias é O(n) — você precisa percorrer ponteiro por ponteiro. Por isso listas ligadas geralmente usam busca linear, mesmo que estejam ordenadas. Arrays, por terem acesso aleatório O(1), são a estrutura ideal para busca binária.
Busca em estruturas não-lineares
Árvores e grafos representam relações hierárquicas ou conexões entre nós. Algoritmos como Busca em Largura (BFS) e Busca em Profundidade (DFS) exploram esses nós seguindo regras específicas. BFS visita primeiro os vizinhos imediatos antes de aprofundar, garantindo o caminho mais curto em grafos não ponderados. DFS mergulha o mais fundo possível antes de retroceder, sendo útil para detecção de ciclos, ordenação topológica e exploração de espaços de estado.

Árvores binárias de busca (BST) e suas variações balanceadas (AVL, Red-Black, B-Trees) oferecem busca O(log n) em estruturas hierárquicas. São a base de índices em bancos de dados como MySQL e PostgreSQL, que usam B-Trees para localizar registros sem varrer a tabela inteira.
Para que servem os Algoritmos de Busca?
Algoritmos de busca estão no coração de qualquer sistema que precise recuperar dados rapidamente. Em bancos de dados relacionais, índices baseados em B-Trees permitem localizar uma linha específica em uma tabela com bilhões de registros sem fazer full table scan. Sem essa otimização, queries simples levariam minutos ou horas.
Em motores de busca como Google, Bing e DuckDuckGo, algoritmos de busca operam sobre índices invertidos — estruturas que mapeiam termos para listas de documentos. Quando você pesquisa “marketing digital B2B”, o motor não varre toda a web; ele consulta o índice e retorna documentos relevantes em milissegundos. Tecnologias como Elasticsearch e Apache Solr aplicam o mesmo princípio para busca textual em aplicações corporativas.
Em sistemas de e-commerce, algoritmos de busca alimentam funcionalidades como filtros de catálogo, autocomplete na barra de pesquisa e recomendações baseadas em similaridade. Um catálogo com 100 mil produtos precisa responder a uma consulta de autocomplete em menos de 100ms para não prejudicar a experiência do usuário — algo impossível sem estruturas indexadas e algoritmos otimizados.
Outras aplicações incluem roteamento de redes (Dijkstra, A*), compiladores (busca em tabelas de símbolos), sistemas operacionais (busca em tabelas de páginas), criptografia (busca em estruturas hash) e inteligência artificial (busca em espaços de estado para resolução de problemas).
Tipos de Algoritmos de Busca
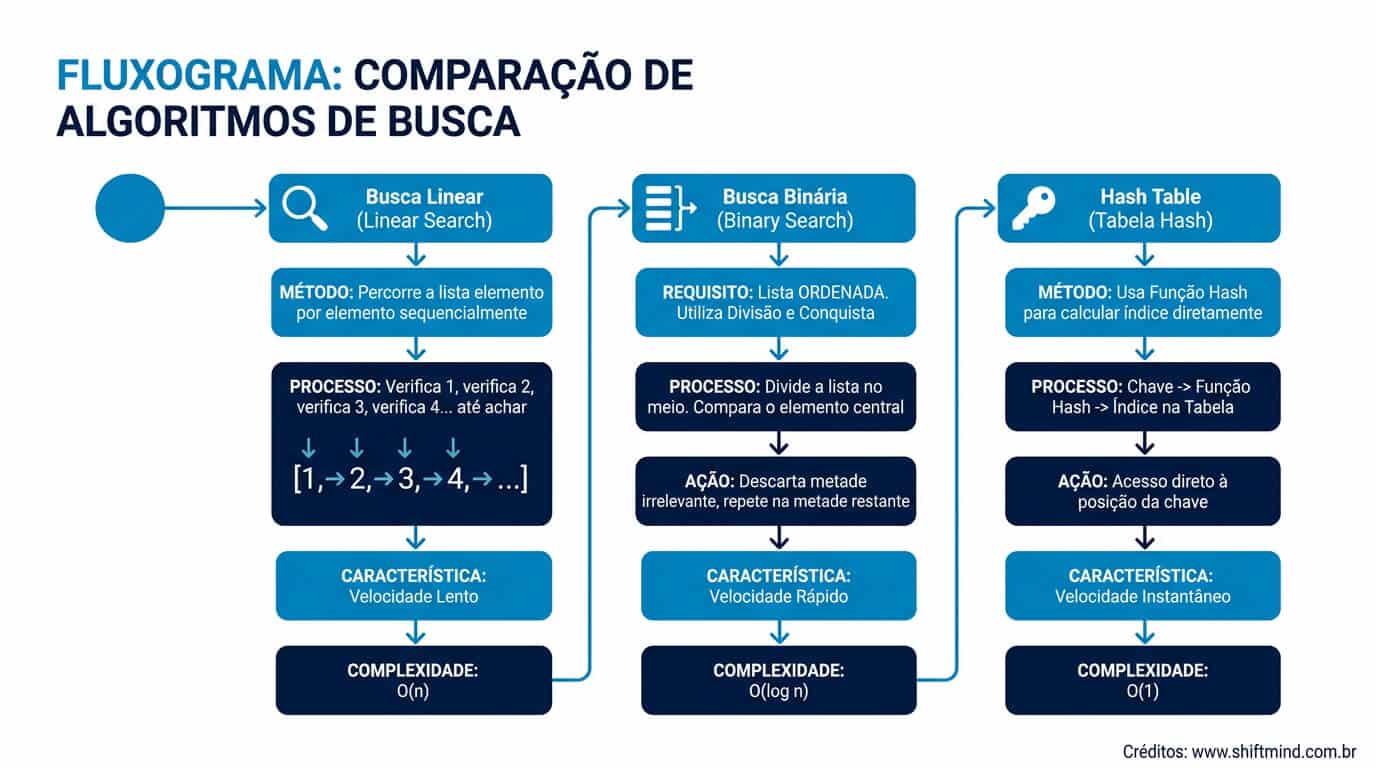
Existem dezenas de algoritmos de busca, mas três categorias dominam o desenvolvimento de software: busca linear, busca binária e busca em estruturas não-lineares (árvores e grafos). Cada uma resolve um problema diferente e tem trade-offs específicos.
Busca linear (sequencial)
A busca linear percorre cada elemento de uma coleção do início ao fim, comparando com a chave de busca. É o algoritmo mais simples e funciona em qualquer estrutura iterável, ordenada ou não. Sua complexidade é O(n) no pior caso — se o elemento estiver na última posição ou não existir, todos os n elementos serão verificados.
Exemplo conceitual em um array de 8 elementos buscando o valor 17:
Array: [3, 8, 12, 5, 17, 22, 1, 9]
Índice: 0 1 2 3 4 5 6 7
Buscando 17: compara 3, 8, 12, 5, 17 — encontrado no índice 4 após 5 comparações.

É adequada para coleções pequenas (menos de 100 elementos), dados não ordenados ou quando você precisa encontrar todas as ocorrências de um valor (não apenas a primeira). Também é a única opção em estruturas que não suportam acesso aleatório eficiente, como listas ligadas e streams.
Busca binária
A busca binária opera em arrays ordenados e divide o espaço de busca pela metade a cada iteração. Compara o elemento do meio com a chave: se for igual, retorna; se a chave for menor, busca na metade esquerda; se for maior, na direita. Sua complexidade é O(log n), o que significa que buscar em 1 milhão de elementos requer no máximo 20 comparações.
Exemplo conceitual em um array ordenado buscando o valor 17:
Array ordenado: [1, 3, 5, 8, 9, 12, 17, 22]
Índices: 0 1 2 3 4 5 6 7
Iteração 1: meio = índice 3 (valor 8). 17 maior que 8, busca à direita.
Iteração 2: meio = índice 5 (valor 12). 17 maior que 12, busca à direita.
Iteração 3: meio = índice 6 (valor 17). Encontrado em 3 comparações.
Comparativo de performance: em um array de 1 milhão de elementos, a busca linear faz em média 500.000 comparações; a busca binária faz no máximo 20. A diferença é de 25.000 vezes mais rápida. Por isso, sempre que houver dados ordenados e buscas frequentes, a busca binária deve ser preferida.

Busca em árvores e grafos (BFS/DFS)
Quando os dados têm estrutura hierárquica ou de rede, busca linear e binária não se aplicam. Para árvores binárias de busca, a operação de busca segue a ordem dos nós: vai para a esquerda se a chave for menor, para a direita se for maior. Em árvores balanceadas, a complexidade é O(log n).
BFS (Breadth-First Search): explora todos os vizinhos do nó atual antes de avançar para o próximo nível. Usa uma fila (FIFO) para gerenciar os nós a visitar. Garante o caminho mais curto em grafos não ponderados. Aplicações: sugestão de amigos em redes sociais, web crawlers que respeitam profundidade, encontrar conexões mínimas.
DFS (Depth-First Search): explora um caminho até o fim antes de retroceder. Usa uma pilha (LIFO) ou recursão. Aplicações: detecção de ciclos em grafos, ordenação topológica, resolução de labirintos, parsing de árvores sintáticas em compiladores.
Ambos têm complexidade O(V + E), onde V é o número de vértices e E o número de arestas. A escolha entre BFS e DFS depende do problema: se você precisa do caminho mais curto, BFS; se precisa explorar todas as possibilidades sem se importar com a ordem, DFS.
Complexidade comparada (Big O)
A tabela abaixo resume a complexidade de tempo dos principais algoritmos de busca em cenários de melhor, médio e pior caso:
| Algoritmo | Melhor caso | Caso médio | Pior caso | Espaço |
|---|---|---|---|---|
| Busca Linear | O(1) | O(n) | O(n) | O(1) |
| Busca Binária | O(1) | O(log n) | O(log n) | O(1) |
| Busca em Árvore Binária (balanceada) | O(1) | O(log n) | O(log n) | O(n) |
| Busca em Árvore Binária (não balanceada) | O(1) | O(log n) | O(n) | O(n) |
| Hash Table (lookup) | O(1) | O(1) | O(n) | O(n) |
| BFS | O(1) | O(V + E) | O(V + E) | O(V) |
| DFS | O(1) | O(V + E) | O(V + E) | O(V) |
| Busca Interpolada | O(1) | O(log log n) | O(n) | O(1) |
O melhor caso geralmente acontece quando o elemento está na primeira posição verificada. O caso médio reflete o desempenho esperado em uso real. O pior caso é o cenário mais desfavorável — é o que você deve considerar ao projetar sistemas que precisam de garantias de tempo de resposta (real-time, sistemas embarcados, APIs com SLA).
Vantagens e desvantagens de cada tipo de busca
Busca linear:
- Vantagens: simplicidade extrema, funciona em qualquer estrutura, não exige pré-processamento, ideal para dados pequenos ou não ordenados.
- Desvantagens: performance ruim em coleções grandes, complexidade O(n) inviabiliza uso em sistemas de alta escala.
Busca binária:
- Vantagens: extremamente rápida (O(log n)), eficiente em arrays grandes, baixo consumo de memória.
- Desvantagens: exige dados ordenados (custo O(n log n) para ordenar), não funciona bem em listas ligadas, difícil de adaptar para inserções/remoções frequentes.
Busca em árvores:
- Vantagens: equilibra busca, inserção e remoção em O(log n), suporta operações de range (buscar elementos entre X e Y), base de índices em bancos de dados.
- Desvantagens: árvores não balanceadas degradam para O(n), implementação mais complexa, consumo de memória adicional para ponteiros.
Hash Tables:

- Vantagens: busca, inserção e remoção em O(1) médio, ideal para lookups frequentes.
- Desvantagens: não mantém ordem dos elementos, colisões degradam performance, alto consumo de memória, não suporta range queries.
BFS/DFS:
- Vantagens: únicas opções para grafos e árvores genéricas, BFS garante caminho mínimo, DFS economiza memória em grafos profundos.
- Desvantagens: BFS consome muita memória em grafos largos, DFS pode ficar preso em ciclos sem controle de visitados, não se aplicam a estruturas lineares simples.
Erros comuns ao implementar busca
Mesmo desenvolvedores experientes cometem erros ao implementar algoritmos de busca em produção. Os mais frequentes são:
1. Aplicar busca binária em dados não ordenados: a busca binária pressupõe ordenação. Aplicá-la em arrays não ordenados retorna resultados incorretos sem gerar erro explícito — o pior tipo de bug, porque passa despercebido em testes superficiais.
2. Usar busca linear em coleções grandes: trabalhar com arrays de 100 mil ou 1 milhão de elementos com busca linear em loops aninhados gera complexidade O(n²) ou pior. Sistemas que funcionam em desenvolvimento (com dados pequenos) travam em produção.
3. Ignorar overflow no cálculo do meio em busca binária: a fórmula meio = (inicio + fim) / 2 pode estourar inteiros em arrays muito grandes. A versão segura é meio = inicio + (fim - inicio) / 2. Esse bug ficou famoso por estar presente na implementação de busca binária do Java SE durante quase uma década.
4. Não tratar o caso ‘elemento não encontrado’: retornar -1, null ou lançar exceção? Definir e documentar o contrato é essencial. Ignorar esse caso gera NullPointerException em chamadores que assumiam sucesso.
5. Esquecer de marcar nós visitados em BFS/DFS: em grafos com ciclos, não manter um conjunto de nós visitados causa loops infinitos. Esse erro é clássico em algoritmos de web crawling, exploração de redes sociais e análise de dependências.
6. Usar hash table sem dimensionar adequadamente: hash tables com fator de carga alto degradam para O(n) por colisões. Tabelas pequenas demais geram colisões excessivas; grandes demais desperdiçam memória. O fator de carga ideal fica entre 0,6 e 0,75.
7. Confiar em busca linear quando o banco de dados oferece índice: rodar uma query com LIKE de wildcard duplo sem índice apropriado força full table scan. Para busca textual, usar índices fulltext, Elasticsearch ou soluções especializadas é obrigatório em catálogos com mais de 10 mil registros.
Algoritmo de Busca e a Shiftmind
Algoritmos de busca eficientes são a espinha dorsal de qualquer aplicação web profissional. Em sites WordPress, eles definem a velocidade de carregamento de páginas com muitos posts; em e-commerces, garantem que o cliente encontre o produto certo em milissegundos; em sistemas corporativos, viabilizam relatórios em tempo real sobre milhões de registros.
A Shiftmind atua na concepção e implementação de aplicações web que dependem de algoritmos de busca otimizados. Em projetos de criação de sites WordPress, configuramos índices, plugins de busca avançada e estruturas de cache que aceleram a recuperação de conteúdo. Em iniciativas de desenvolvimento WordPress sob medida, projetamos camadas de dados que suportam buscas complexas em catálogos, áreas de membros e sistemas de gestão.
Em projetos de e-commerce B2B, implementamos motores de busca facetada com Elasticsearch ou soluções equivalentes, garantindo autocomplete em tempo real, filtros multivariáveis e relevância ranqueada para catálogos com dezenas de milhares de SKUs. Para empresas que combinam tecnologia com geração de demanda, nossa expertise em marketing digital B2B integra algoritmos de busca a estratégias de SEO, lead scoring e personalização de conteúdo.
Após o lançamento, mantemos a performance estável através do serviço de suporte e manutenção, monitorando índices, otimizando queries lentas e ajustando estruturas conforme o volume de dados cresce. Algoritmo de busca não é apenas teoria de computação — é um diferencial competitivo concreto para qualquer negócio digital.
Termos relacionados
- Algoritmo
- Abstração
- Acoplamento
- ActiveRecord
- Agile (Metodologia Ágil)
- AJAX
- API
- Estrutura de Dados
- Big O
- Hash Table
- Árvore Binária
- BFS
- DFS
- Elasticsearch
- MySQL Index
Conclusão
Algoritmos de busca são ferramentas fundamentais para qualquer desenvolvedor que constrói sistemas escaláveis. Dominar busca linear, busca binária e algoritmos para árvores e grafos (BFS, DFS) permite escolher a abordagem certa para cada problema, evitando gargalos de performance que comprometem a experiência do usuário e a viabilidade técnica do produto.
A regra prática é: para coleções pequenas ou dados não ordenados, busca linear basta; para arrays grandes e ordenados, busca binária é imbatível; para estruturas hierárquicas e relacionais, árvores balanceadas e algoritmos de grafo são indispensáveis. Em todos os casos, conhecer a complexidade Big O do algoritmo é essencial para tomar decisões embasadas.
Precisa construir um site ou aplicação web que entrega resultados rápidos mesmo com grandes volumes de dados? A Shiftmind projeta soluções WordPress, e-commerces e sistemas corporativos com performance e escalabilidade desde a fundação. Fale com nosso time e descubra como transformar tecnologia em vantagem competitiva.
