

Auto Scaling é o mecanismo de computação em nuvem que ajusta automaticamente a quantidade de recursos computacionais alocados a uma aplicação conforme a demanda real, adicionando ou removendo instâncias, contêineres ou capacidade de máquinas virtuais sem intervenção manual. Em vez de provisionar servidores fixos para o pico hipotético, o Auto Scaling observa métricas em tempo real (CPU, memória, requisições por segundo, profundidade de fila) e dispara políticas pré-configuradas para escalar a infraestrutura para cima quando há pressão e para baixo quando há ociosidade, alinhando custo e capacidade à curva de uso.
Esse modelo é uma das maiores vantagens econômicas e arquiteturais da nuvem pública: transforma capacidade de TI em utility computing, onde se paga somente pelo que é consumido. Para um e-commerce B2B na Black Friday, um portal de mídia em momento de tráfego viral ou uma API de pagamento em horário comercial, o Auto Scaling significa entregar performance previsível sem manter frota superdimensionada 24 horas por dia.
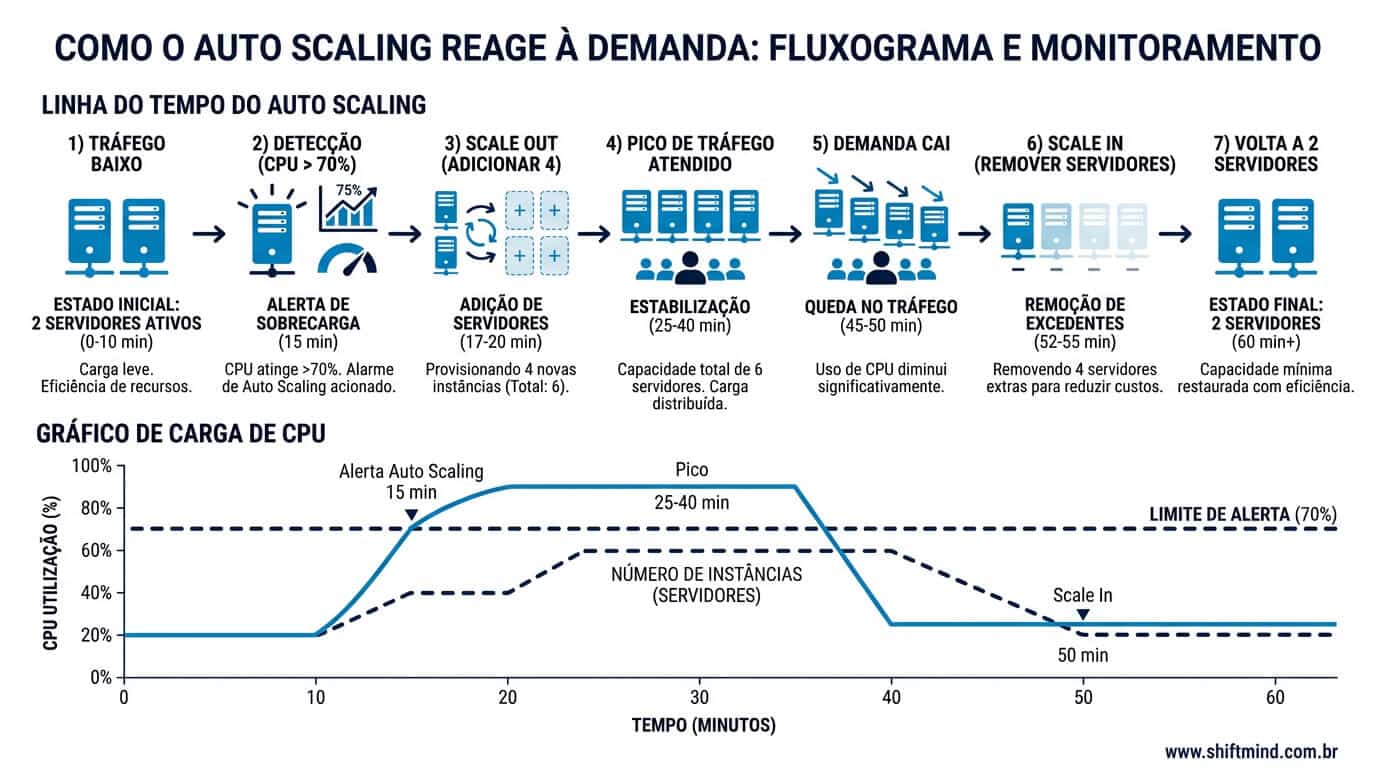

Como funciona o Auto Scaling?
Na prática, o Auto Scaling é um sistema de controle baseado em três pilares: coleta contínua de métricas, avaliação de regras (policies) e ação de provisionamento. Quando uma métrica monitorada cruza um limiar definido, o serviço de scaling executa uma ação no grupo de instâncias — adicionar nós, remover nós ou ajustar capacidade vertical — e aguarda um período de estabilização antes de tomar nova decisão.
Triggers e métricas
Os triggers são as condições que disparam a ação de escalonamento. As métricas mais usadas são utilização de CPU, consumo de memória, número de requisições HTTP por segundo (RPS), latência média, profundidade de filas SQS ou RabbitMQ e métricas customizadas de aplicação (sessões ativas, jobs pendentes, conexões de banco). Em ambientes maduros, monitora-se a métrica que reflete o gargalo real da aplicação — para uma API CPU-bound, CPU faz sentido; para um worker assíncrono, profundidade de fila é mais preciso; para um servidor WordPress com PHP-FPM, número de workers ocupados é o sinal correto.
Scaling policies
As políticas definem como o sistema reage ao trigger. Existem três famílias principais: simple scaling (adiciona ou remove um número fixo de instâncias quando o limiar é cruzado), step scaling (escala em degraus proporcionais à intensidade do desvio — quanto mais distante do alvo, mais agressiva a ação) e target tracking (define-se um alvo, por exemplo, 60% de CPU médio no grupo, e o serviço calcula sozinho quantas instâncias adicionar ou remover para manter o alvo). Target tracking é o padrão moderno por ser autoajustável e exigir menos calibração manual.
Cooldown periods
O cooldown é o intervalo após uma ação de scaling no qual nenhum novo evento é avaliado. Existe para evitar oscilação (thrashing) — instâncias sendo criadas e destruídas em ciclos curtos por causa do ruído natural das métricas. O valor típico fica entre 180 e 600 segundos, ajustável de acordo com o tempo de boot da aplicação. Uma instância EC2 que sobe em 90 segundos pode usar cooldown de 180 segundos; um nó Kubernetes que demora 4 minutos para ficar pronto exige cooldown maior, sob risco de tomar decisões com base em métricas obsoletas.
Para que serve o Auto Scaling?
O Auto Scaling cumpre três objetivos centrais: economia, disponibilidade e resposta a picos de demanda. Sob a ótica financeira, ele elimina o desperdício de manter capacidade ociosa durante a madrugada, fins de semana ou períodos de baixa atividade — uma loja online B2B que opera majoritariamente em horário comercial pode rodar com 30% da capacidade fora do expediente, gerando economia mensal de 40% a 70% comparado a um cluster fixo.

E-book – Tudo sobre Automação de Marketing
E-book – Tudo sobre Automação de Marketing
Mais Informações
Do ponto de vista de disponibilidade, o Auto Scaling se integra a health checks: instâncias com falha são substituídas automaticamente, mantendo o número mínimo definido no grupo. Isso traz autorrecuperação real, não apenas elasticidade. E quanto a picos de demanda, é a única forma economicamente viável de absorver eventos como Black Friday, lançamentos virais, campanhas de mídia paga ou efeitos cascata de menção em grande veículo sem causar lentidão ou queda do serviço.
Tipos de Auto Scaling
Vertical scaling (scale up/down)
O scaling vertical altera o tamanho da própria instância — sobe uma máquina de 4 vCPUs e 8 GB para 16 vCPUs e 32 GB, por exemplo. É indicado para workloads que não escalam horizontalmente bem, como bancos de dados monolíticos, aplicações stateful pesadas ou softwares legados com licenciamento por servidor. A limitação é clara: existe um teto físico (a maior instância disponível) e geralmente requer reinício ou janela de manutenção. Na AWS, isso é feito via stop, change instance type e start; no Azure, via redimensionamento de VM.
Horizontal scaling (scale out/in)
O scaling horizontal adiciona ou remove instâncias idênticas em paralelo, distribuindo a carga via Load Balancer. É o modelo padrão para aplicações cloud-native, web servers, APIs REST, microsserviços e workers de processamento. Exige que a aplicação seja stateless (ou que o estado fique externalizado em Redis, banco de dados ou armazenamento compartilhado), mas em troca oferece elasticidade praticamente ilimitada e maior resiliência — a perda de um nó não derruba o serviço.
Predictive scaling
O scaling preditivo usa machine learning para analisar padrões históricos de tráfego e provisionar capacidade antecipadamente, antes que o pico aconteça. AWS Predictive Scaling, por exemplo, identifica ciclos diários e semanais e adiciona instâncias 15 a 30 minutos antes do horário previsto de aumento. É útil para aplicações com padrões fortemente sazonais — newsletter enviada todas as terças às 9h, lojas que abrem às 8h, sistemas internos com pico de login no início do expediente. Funciona melhor combinado com reactive scaling (target tracking) para cobrir eventos não previstos.
Auto Scaling nos principais provedores
AWS Auto Scaling é o serviço mais maduro do mercado, abrangendo EC2 Auto Scaling Groups, Application Auto Scaling (ECS, DynamoDB, Aurora, Lambda concurrency) e Predictive Scaling. Integra-se nativamente com Elastic Load Balancer, CloudWatch e CloudFormation, suportando políticas target tracking, step scaling, scheduled scaling e instance refresh para deploys rolling.

Azure Virtual Machine Scale Sets (VMSS) é a contraparte na nuvem da Microsoft, com integração profunda em Azure Monitor, Application Insights e Azure Load Balancer. Oferece autoscale baseado em métricas, em agendamento e em métricas customizadas via Application Insights, além de suporte a instâncias spot mescladas com on-demand para reduzir custos.
Google Cloud Managed Instance Groups (MIGs) são a solução no GCP, com autoscaling baseado em CPU, métricas Stackdriver, carga de balanceador HTTP(S) ou métricas customizadas. O diferencial do Google é o suporte nativo a multi-zona e multi-regional MIGs, que distribuem instâncias automaticamente entre zonas para resiliência. Para containers, Kubernetes oferece HPA (Horizontal Pod Autoscaler), VPA (Vertical Pod Autoscaler) e Cluster Autoscaler, disponíveis nas três nuvens via serviços gerenciados (EKS, AKS, GKE).
Vantagens e desvantagens do Auto Scaling
Vantagens: redução significativa de custo operacional ao alinhar gasto ao consumo real; absorção transparente de picos sazonais; autorrecuperação por substituição automática de instâncias com falha; alta disponibilidade ao espalhar carga entre múltiplas zonas; redução da carga operacional do time de infraestrutura, que deixa de fazer ajustes manuais; suporte natural a deploys blue/green e rolling.
Desvantagens e custos: exige que a aplicação seja arquitetada para stateless (ou ao menos com estado externalizado), o que pode demandar refatoração; aumenta a complexidade de troubleshooting — debugar problemas em frota dinâmica é mais difícil que em servidor fixo; tempo de boot das instâncias cria janela de degradação durante picos abruptos (mitigável com warm pools); custos podem escalar de forma inesperada se thresholds estiverem mal calibrados ou em caso de ataques (DDoS gerando autoscale descontrolado); requer disciplina em observabilidade e em testes de carga para validar comportamento.
Erros comuns ao configurar Auto Scaling
1. Thresholds mal calibrados: definir CPU em 80% como gatilho de scale-up parece razoável, mas se a aplicação degrada a partir de 60%, o usuário já está enfrentando lentidão antes da ação. O thresholds correto vem de teste de carga, não de palpite.

2. Cooldown muito curto: cooldowns de 60 segundos em aplicações que demoram 3 minutos para subir geram thrashing e custos altos com instâncias incompletas. Sempre alinhar cooldown ao tempo real de boot mais um buffer.
3. Escalar o gargalo errado: um banco PostgreSQL saturado não é resolvido adicionando mais servidores de aplicação — pelo contrário, mais conexões pioram a situação. É essencial identificar o gargalo real (CPU, IO, banco, cache) antes de definir a política de scaling.
4. Ignorar o aquecimento (warm-up): instâncias recém-criadas têm cache vazio, conexões de banco frias e JIT compilers ainda não otimizados. Direcionar 100% do tráfego imediatamente causa degradação. Configurar warm-up time no health check do Load Balancer é fundamental.
5. Não testar o scale-down: times configuram bem o scale-up, mas esquecem que o scale-in remove instâncias — e se a aplicação não trata sinais SIGTERM corretamente, sessões e jobs em andamento são perdidos. Implementar graceful shutdown e connection draining no Load Balancer é obrigatório.
6. Falta de limites máximos: grupos sem max size definido podem escalar indefinidamente em caso de loop de erro ou ataque, gerando faturas catastróficas. Sempre definir teto compatível com a capacidade orçamentária e com a infraestrutura downstream (banco, APIs externas).

Cenário Black Friday e-commerce: uma loja B2B que processa em média 200 pedidos/hora pode atingir 8.000 pedidos/hora no pico da Black Friday. Sem Auto Scaling, manter 40x a capacidade ano todo é insustentável; com configuração correta — target tracking de 50% CPU, step scaling para picos abruptos, predictive scaling baseado no histórico do ano anterior, warm pool com instâncias pré-inicializadas — a infraestrutura cresce de 4 para 80 instâncias em poucos minutos, atende a demanda e retorna ao baseline no dia seguinte sem intervenção manual.
Auto Scaling e a Shiftmind
Implementar Auto Scaling de forma confiável exige infraestrutura sólida, observabilidade adequada e arquitetura preparada para elasticidade. A Shiftmind atua exatamente nesse ponto, oferecendo soluções de hospedagem e infraestrutura que sustentam aplicações críticas em ambientes de tráfego variável.
Para projetos que exigem controle total e capacidade dedicada, o servidor dedicado da Shiftmind oferece a base ideal para clusters próprios ou ambientes hÍbridos. Para sites WordPress de alta performance, a hospedagem WordPress e a hospedagem gerenciada entregam stack otimizada com cache, CDN e provisionamento elástico para suportar picos sem degradação. O serviço de suporte e manutenção garante que as configurações de scaling sejam revisadas continuamente, evitando os erros descritos acima. Para operações B2B com fluxos transacionais intensos, o e-commerce B2B da Shiftmind combina arquitetura escalável e infraestrutura preparada para campanhas sazonais como Black Friday e lançamentos de produto.
Termos relacionados
- Alta Disponibilidade (High Availability) — Auto Scaling é peça central da HA em arquiteturas cloud
- Afinidade de Sessão (Session Affinity) — relevante ao escalar aplicações com estado
- Armazenamento em Nuvem — base para externalizar estado em ambientes elásticos
- API Gateway — frequentemente combinado com Auto Scaling em arquiteturas de microsserviços
- APM (Application Performance Monitoring) — fornece métricas customizadas para políticas de scaling
- Apache — servidor web frequentemente colocado atrás de grupos auto-scalados
- Apache Kafka — usado para absorver picos antes de processar com workers escalados
- Ansible — automatiza provisionamento de instâncias dentro de grupos de scaling
- ACL (Access Control List) — controle de acesso em ambientes dinâmicos com instâncias efêmeras
- Active Directory — integração de identidade em frotas escaláveis
- AMD EPYC — processadores comuns em instâncias usadas em grupos de scaling
- AppArmor — endurecimento de segurança em imagens base usadas em scaling
- Appliance — alternativa fixa contrastante com modelo elástico
- ARM Server — opções de instâncias ARM para reduzir custo em scaling horizontal
Conceitos complementares como Load Balancer, Kubernetes HPA, AWS Auto Scaling, Azure VMSS, CloudWatch, Black Friday e e-commerce também são fundamentais para compor uma estratégia completa de elasticidade na nuvem.
Conclusão
O Auto Scaling deixou de ser um diferencial e tornou-se requisito básico para qualquer aplicação séria em nuvem. Ele alinha custo a consumo, entrega resiliência por design e permite que aplicações B2B atendam picos sazonais sem manter frota superdimensionada. A configuração correta — target tracking bem calibrado, cooldowns adequados, gargalo identificado, warm-up e limites máximos definidos — separa ambientes que economizam e escalam dos que sangram dinheiro ou caem nos momentos críticos.

Se a sua operação depende de WordPress de alto tráfego, e-commerce B2B com sazonalidade, APIs com picos diários ou qualquer carga sujeita a variação, vale revisar a arquitetura sob a ótica da elasticidade. A Shiftmind ajuda empresas a desenhar, implementar e operar infraestruturas que escalam de forma previsível e econômica. Entre em contato e converse com nosso time sobre como aplicar Auto Scaling ao seu cenário.
