

Alta Disponibilidade (High Availability, ou HA) é a capacidade de um sistema permanecer operacional e acessível por longos períodos, minimizando interrupções planejadas e não planejadas. Na prática, significa arquitetar servidores, redes e aplicações com redundância suficiente para que falhas isoladas não derrubem o serviço. O objetivo mais comum é alcançar SLAs de 99,9% a 99,999% de uptime, o que permite no máximo algumas dezenas de minutos de indisponibilidade por ano.
Para uma empresa B2B, indisponível durante 1 hora em horário comercial pode significar perda de leads qualificados, quebra de contratos de SLA com clientes corporativos e danos de reputação que levam meses para serem reparados. Por isso, projetar HA deixou de ser luxo reservado a bancos e operações críticas: hoje é requisito básico de qualquer site institucional, e-commerce ou plataforma SaaS que leve o negócio a sério.
Como funciona Alta Disponibilidade?
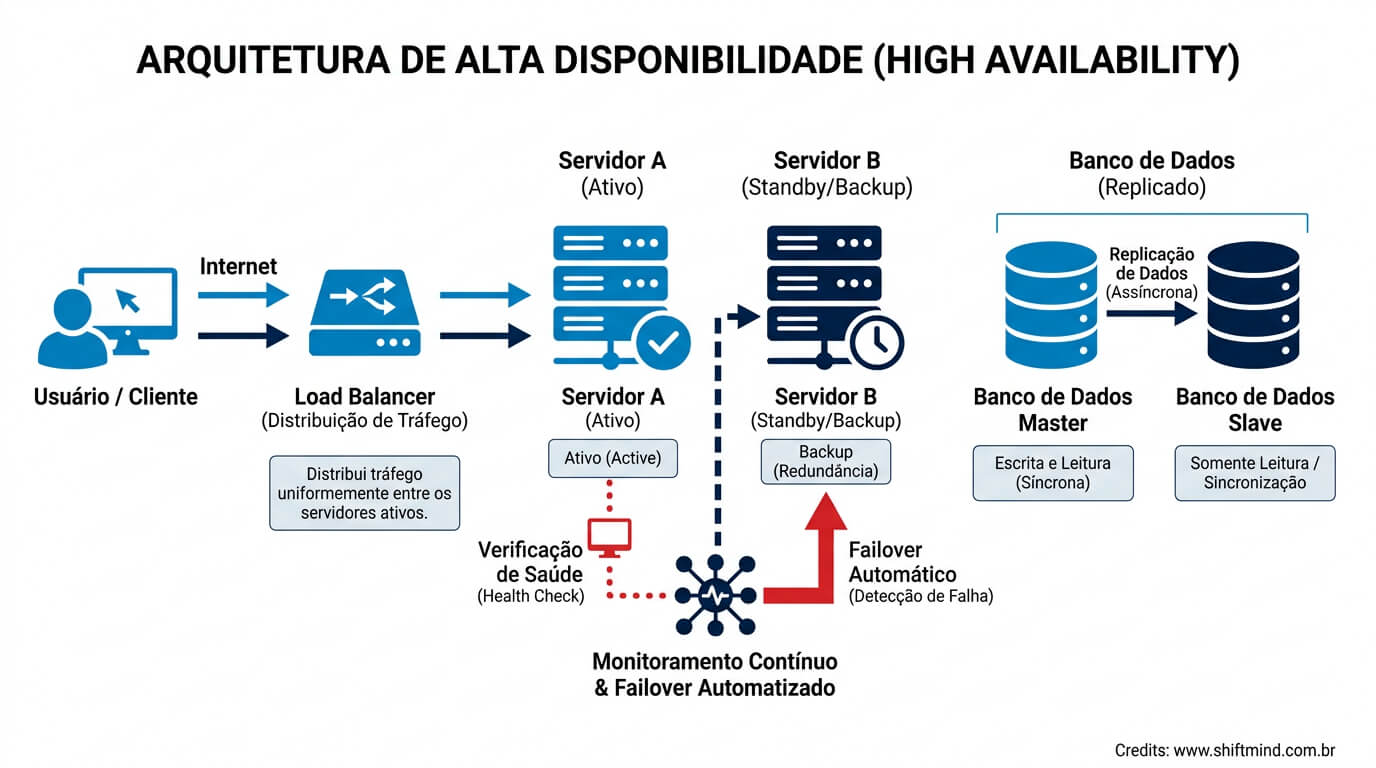
A Alta Disponibilidade não depende de um único recurso mágico. Ela é resultado de quatro pilares trabalhando juntos: redundância de componentes, mecanismo de failover, distribuição de carga e monitoramento contínuo. Quando qualquer um desses pilares é negligênciado, o sistema inteiro herda uma fragilidade invisível que só aparece no pior momento possível.

Redundância
Redundância significa ter mais de um componente cumprindo o mesmo papel. Em vez de um servidor web, dois ou mais em nós distintos. Em vez de um banco de dados, uma topologia com réplica síncrona ou assíncrona. Em vez de um link de internet, dois provedores diferentes. A regra de ouro é eliminar todo Single Point of Failure (SPOF): qualquer peça cuja falha derrube o sistema inteiro precisa ser duplicada.
Failover
Failover é o mecanismo que promove automaticamente um componente redundante quando o ativo falha. Ferramentas como Keepalived, Pacemaker e HAProxy monitoram a saúde dos nós e redirecionam tráfego em segundos. Um bom failover precisa ser transparente para o usuário final, idempotente (não pode causar inconsistência ao reexecutar) e ter um tempo de convergência previsível, normalmente entre 5 e 30 segundos.
Load Balancing
O balanceamento de carga distribui requisições entre múltiplos servidores usando algoritmos como round-robin, least connections ou weighted. Isso aumenta a capacidade total e, principalmente, garante que a queda de um nó seja absorvida pelos demais sem impacto percebido. Load balancers modernos (NGINX, HAProxy, AWS ELB, Cloudflare) ainda aplicam health checks constantes, removendo nós doentes do pool antes que o cliente sinta qualquer lentidão.
Monitoramento
Sem observabilidade, HA vira loteria. Ferramentas como Prometheus, Zabbix, Datadog e New Relic coletam métricas de CPU, memória, latency, error rate e filas, disparando alertas antes que o problema escale. O time de operações precisa de dashboards em tempo real, runbooks atualizados e testes periódicos de caos (chaos engineering) para validar que o failover realmente funciona sob pressão.

Para que serve Alta Disponibilidade?
Alta Disponibilidade serve, antes de tudo, para garantir continuidade de negócio. Em operações digitais, cada minuto de indisponibilidade gera consequências em cascata: transações perdidas, abandono de carrinho, penalidade em rankings de busca e desgaste do relacionamento com clientes.
HA também é essencial para cumprir contratos de SLA. Empresas que vendem software ou serviços para grandes contas assinam acordos prometendo determinado nível de disponibilidade, com multas pesadas em caso de descumprimento. Sem uma arquitetura de HA bem desenhada, o vendor entra em um ciclo de créditos de serviço que corrói margem e ameaça a sobrevivência do contrato.
No aspecto financeiro, o custo do downtime é o argumento definitivo. Segundo relatório da Gartner, a hora de indisponibilidade em empresas de médio e grande porte custa em média US$ 5.600 por minuto, o equivalente a aproximadamente US$ 336 mil por hora. Em verticais como serviços financeiros e e-commerce de grande porte, esse número pode ultrapassar US$ 1 milhão por hora em picos sazonais como Black Friday.
Exemplos de Alta Disponibilidade na prática
Exemplo 1: Cluster MySQL com replicação master-master
Um SaaS B2B brasileiro operando com milhares de tenants não pode depender de um único servidor MySQL. A solução clássica é configurar um cluster com dois nós em replicação master-master usando Galera Cluster ou Percona XtraDB. Um proxy como ProxySQL decide para onde mandar leituras e escritas, e se um nó cai, o outro continua servindo sem perder transações. O resultado é um RPO (Recovery Point Objective) próximo de zero e um RTO (Recovery Time Objective) de poucos segundos.
Exemplo 2: WordPress multi-servidor para e-commerce B2B
Um e-commerce B2B de autopeças faturando sete dígitos por mês não pode cair em horário de faturamento. A arquitetura típica envolve dois ou mais servidores web com WordPress, um banco MySQL em cluster, um Redis compartilhado para sessões e object cache, um storage NFS ou S3 para o wp-content/uploads e um load balancer à frente. Plugins como W3 Total Cache e WP Rocket ajudam a distribuir a carga, enquanto o Cloudflare atua como camada extra de cache e proteção contra DDoS. Essa topologia é o mínimo recomendado para quem busca 99,95% de uptime em operações críticas.
Exemplo 3: AWS Multi-AZ para aplicações críticas
Em cloud pública, a abordagem mais comum é distribuir recursos entre múltiplas Availability Zones. No AWS, um Application Load Balancer distribui requisições para instâncias EC2 em pelo menos duas AZs da mesma região. O RDS Multi-AZ provisiona uma réplica síncrona em AZ diferente, com failover automático em 60 a 120 segundos. Serviços gerenciados como ElastiCache e EFS também oferecem configurações Multi-AZ nativas. Essa arquitetura absorve falhas de data center inteiros sem necessidade de intervenção manual.

Níveis de disponibilidade (SLAs)
SLAs de disponibilidade são expressos em percentuais com múltiplos “noves”. Cada nove adicional representa aumento exponencial de complexidade e custo de infraestrutura. A tabela abaixo traduz esses percentuais em tempo real de downtime permitido:
| SLA | Downtime por ano | Downtime por mês | Downtime por semana |
|---|---|---|---|
| 99% (dois noves) | 3 dias, 15 horas e 36 min | 7 horas e 12 min | 1 hora e 40 min |
| 99,9% (três noves) | 8 horas e 45 min | 43 min e 49 seg | 10 min e 4 seg |
| 99,95% | 4 horas e 22 min | 21 min e 54 seg | 5 min e 2 seg |
| 99,99% (quatro noves) | 52 min e 35 seg | 4 min e 22 seg | 1 min e 0 seg |
| 99,999% (cinco noves) | 5 min e 15 seg | 26 seg | 6 seg |
Em projetos reais, 99,9% é o piso mínimo aceitável para operações digitais profissionais. 99,99% é o alvo ideal para e-commerces, SaaS e plataformas B2B com impacto financeiro relevante. 99,999% é território de telecom, sistemas bancários e infraestrutura crítica, exigindo investimento que só se justifica quando cada segundo de downtime tem preço de seis dígitos.
Vantagens e desvantagens da Alta Disponibilidade
Vantagens:

- Redução drástica do risco operacional e financeiro associado a indisponibilidades
- Cumprimento de SLAs contratuais com clientes corporativos e institucionais
- Melhora na experiência do usuçrio e na taxa de conversão
- Proteção de ranking em buscadores (Google penaliza sites instáveis)
- Capacidade de executar manutenções planejadas sem janelas de indisponibilidade perceptíveis
- Maior resiliência contra ataques DDoS e picos inesperados de tráfego
Desvantagens:
- Custo de infraestrutura maior (mínimo 2x o do cenário single-node)
- Complexidade operacional elevada, exigindo equipe especializada em SRE/DevOps
- Maior superfície de ataque e mais componentes para manter atualizados
- Dificuldade em debugar problemas distribuídos (race conditions, split-brain)
- Necessidade de testes frequentes de failover, que consomem tempo do time
Erros comuns ao implementar HA
Arquiteturas de Alta Disponibilidade falham mais por erros de projeto do que por limitação tecnológica. Os cinco erros mais recorrentes em projetos brasileiros são:
- SPOF esquecido em camadas secundárias: a equipe duplica servidores web e banco, mas deixa um único servidor DNS, um único certificado, ou um único storage NFS. Basta uma dessas peças cair para derrubar todo o cluster supostamente redundante.
- Falta de testes reais de failover: muitos times configuram o cluster e nunca testam um desligamento forçado em produção. Quando a falha real acontece, descobrem que o failover nunca funcionou de verdade e o RTO real é de horas, não segundos.
- Replicação assíncrona tratada como síncrona: usar replicação MySQL padrão (assíncrona) e assumir RPO zero é receita para perda de dados. Se o master cai antes de replicar, transações somem. Para RPO zero, é necessário Galera, Group Replication ou soluções equivalentes.
- Split-brain ignorado: quando a rede entre nós falha, cada lado pode se declarar master. Sem mecanismo de quórum ou fencing, a base acaba corrompida e a recuperação vira reconstrução manual de dados.
- Monitoramento só de infraestrutura: monitorar CPU e memória não basta. Se a aplicação retorna 500 em 30% das requisições mas o servidor está com CPU baixa, nenhum alerta dispara. Monitoramento de HA precisa observar métricas de negócio e de aplicação, não só do sistema operacional.
- Backups confundidos com HA: backup e HA resolvem problemas diferentes. HA protege contra falhas de hardware; backup protege contra corrupção de dados, ransomware e erro humano. Projetos sérios precisam dos dois, nunca apenas um.
- Capacidade subdimensionada em modo degradado: quando um nó de dois cai, o único restante passa a receber 100% do tráfego. Se cada nó estava operando a 70%, o sobrevivente vai saturar e cair logo em seguida, causando efeito dominó.
Alta Disponibilidade e a Shiftmind
Implementar Alta Disponibilidade exige planejamento de arquitetura, infraestrutura adequada e operação contínua. A Shiftmind ajuda empresas B2B a projetar e operar ambientes HA desde o primeiro servidor até clusters multi-região. Nosso servidor dedicado de alta performance serve como base para clusters redundantes, com hardware confiável, rede de baixa latência e suporte especializado em configuração de failover.
Para projetos WordPress, oferecemos hospedagem WordPress otimizada e hospedagem gerenciada WordPress com cache avançado, CDN integrado e monitoramento 24 horas por dia. Além da infraestrutura, nosso serviço de suporte e manutenção garante que atualizações críticas, ajustes de performance e testes de failover sejam executados com frequência, preservando o SLA acordado. E porque uptime sem segurança é ilusão, incluimos camadas de segurança de websites que protegem o ambiente contra ataques que derrubariam qualquer cluster desprotegido.
Termos relacionados
- ACL (Access Control List)
- Afinidade de Sessão (Session Affinity)
- Active Directory
- Load Balancer
- Failover
- Cluster
- Redundância
- SLA
- Uptime
- Redis
- MySQL Replication
Conclusão
Alta Disponibilidade deixou de ser diferencial e virou requisito operacional para qualquer empresa que dependa de infraestrutura digital para faturar. Mais do que empilhar servidores, HA exige disciplina de arquitetura, testes regulares de failover, monitoramento abrangente e uma cultura operacional que encare indisponibilidade como problema de negócio, não apenas de TI.
Projetar corretamente para 99,99% de uptime significa equilibrar custo, complexidade e risco. Exige eliminar SPOFs, escolher tecnologias de replicação adequadas ao RPO desejado, automatizar failover e documentar runbooks que qualquer plantonista consiga executar às três da manhã. Empresas que investem nessa disciplina colhem diferencial competitivo concreto: menos clientes perdidos, menos multas contratuais e mais credibilidade no mercado B2B.
Precisa projetar uma infraestrutura de Alta Disponibilidade para seu negócio? A Shiftmind pode ajudar com consultoria de arquitetura, servidores dedicados, hospedagem gerenciada e operação contínua. Entre em contato e converse com nossos especialistas em infraestrutura crítica.
