O que é Apache Spark
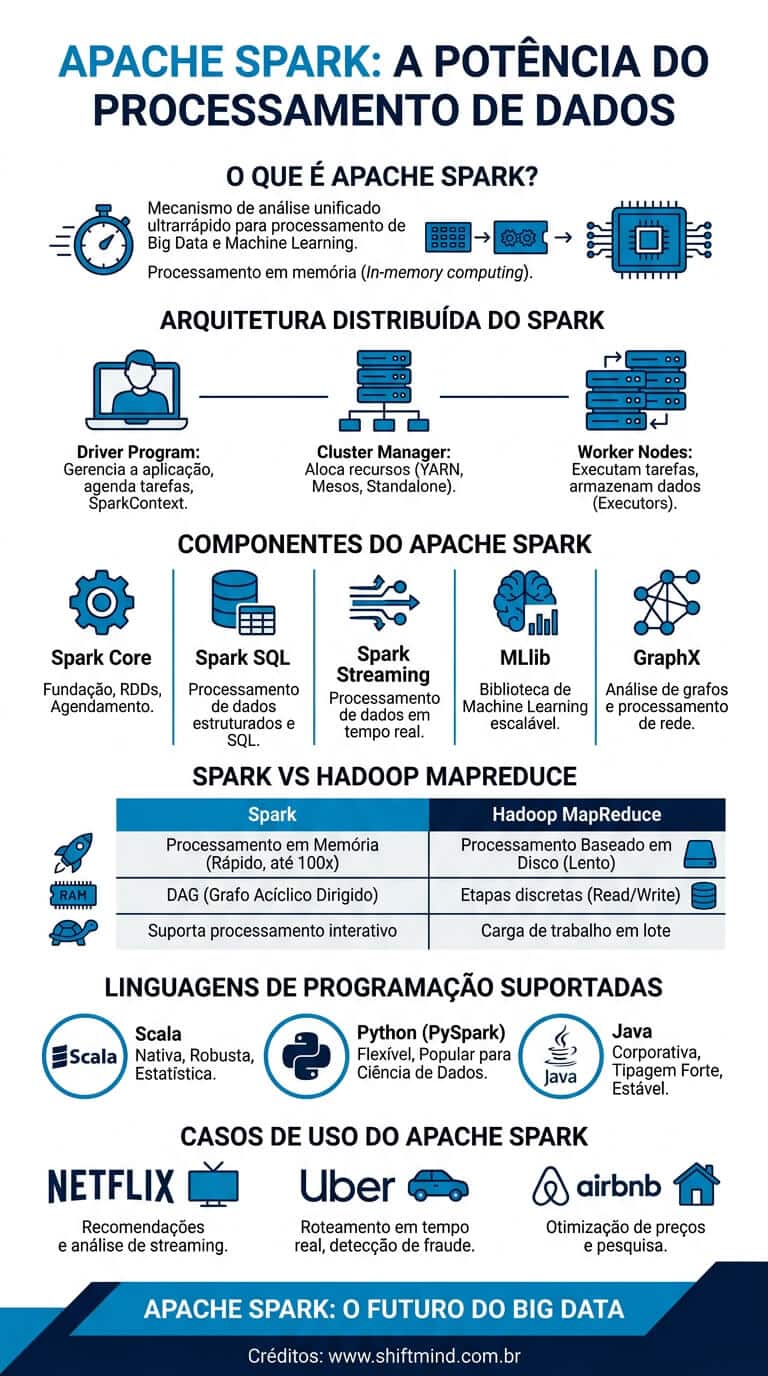
Apache Spark é um framework open-source de computação distribuída para processamento de grandes volumes de dados (Big Data). Criado em 2009 na UC Berkeley e doado à Apache Software Foundation em 2013, o Spark se destaca por processar dados em memória, sendo até 100x mais rápido que o Hadoop MapReduce tradicional para algumas cargas de trabalho.
Spark é usado por gigantes como Netflix, Uber, Airbnb e Pinterest para construir pipelines de ETL, análises em tempo real, modelos de machine learning e processamento de streaming. É um dos pilares do ecossistema moderno de Big Data, frequentemente combinado com Apache Kafka para arquiteturas event-driven.
Componentes principais
- Spark Core: Engine de execução e API base de RDDs
- Spark SQL: Consultas SQL e DataFrames estruturados
- Spark Streaming: Processamento de streams em micro-batches
- MLlib: Biblioteca de machine learning distribuído
- GraphX: Processamento de grafos em larga escala
Linguagens suportadas
Spark suporta Scala (nativa), Python (PySpark — mais popular), Java e R. PySpark domina por causa do ecossistema Python em ciência de dados.

Spark vs Hadoop MapReduce
O grande diferencial do Spark é o processamento in-memory com lazy evaluation: ele monta um DAG (grafo acíclico dirigido) das operações antes de executar, otimizando o plano. MapReduce escreve em disco entre cada etapa, sendo muito mais lento. Por isso o Spark tornou-se padrão para workloads que precisam de velocidade.
Leia o artigo completo: Apache Spark: processamento distribuído de big data em escala